Programma voor het volgen van ping in games. Netwerkmonitoring: hoe we ervoor zorgen dat alle nodes werken voor grote bedrijven
Aan het uiterlijk van deze optiek, die door het bos naar de verzamelaar gaat, kunnen we concluderen dat de installateur de techniek niet een beetje heeft gevolgd. De berg op de foto suggereert ook dat hij waarschijnlijk een zeeman is - een mariene knoop.
Ik zit in het fysieke netwerkgezondheidsteam, met andere woorden, technische ondersteuning, die ervoor zorgt dat de lampjes op de routers knipperen zoals het hoort. Wij hebben onder onze hoede diverse grote bedrijven met infrastructuur door het hele land. We klimmen niet in hun bedrijf, het is onze taak om ervoor te zorgen dat het netwerk op fysiek niveau werkt en dat het verkeer verloopt zoals het hoort.
De algemene betekenis van het werk is constant pollen van nodes, telemetrie verwijderen, testruns (bijvoorbeeld instellingen controleren om kwetsbaarheden te vinden), gezondheid verzekeren, applicaties monitoren, verkeer. Soms voorraden en andere perversies.
Ik zal je vertellen hoe het is georganiseerd en een paar verhalen van de reizen.
Zoals meestal het geval is
Ons team zit in een kantoor in Moskou en neemt netwerktelemetrie. Eigenlijk zijn dit constante pings van knooppunten, evenals het ontvangen van monitoringgegevens als de hardware slim is. De meest voorkomende situatie is dat de ping meerdere keren achter elkaar niet wordt doorgegeven. In 80% van de gevallen bij een winkelketen blijkt dit bijvoorbeeld een stroomstoring te zijn, dus bij het zien van dit plaatje doen we het volgende:- Eerst bellen we de provider over ongevallen
- Dan - naar de energiecentrale over de sluiting
- Dan proberen we een verbinding tot stand te brengen met iemand op de faciliteit (dit is niet altijd mogelijk, bijvoorbeeld om 02.00 uur)
- En ten slotte, als het bovenstaande niet binnen 5-10 minuten heeft geholpen, gaan we weg of sturen we een "avatar" - een contractingenieur die ergens in Izhevsk of Vladivostok zit, als het probleem daar is.
- We houden constant contact met de "avatar" en "leiden" hem door de infrastructuur - we hebben sensoren en servicehandleidingen, hij heeft een tang.
- Dan stuurt de monteur ons een rapport met een foto over wat het was.
De dialoog gaat soms als volgt:
- Dus de verbinding is verbroken tussen gebouw nummer 4 en 5. Controleer de router in de vijfde.
- Bestelling, inbegrepen. Er is geen verbinding.
- Ok, ga langs de kabel naar het vierde gebouw, daar is nog een knoop.
-... Opa!
- Wat er is gebeurd?
- Hier is het 4e huis gesloopt.
- Wat??
- Ik voeg een foto bij het rapport. Ik kan het huis niet herstellen in SLA.

Maar vaker blijkt het toch een pauze te vinden en het kanaal te herstellen.
Ongeveer 60% van de ritten is "in de melk", omdat ofwel de stroomtoevoer wordt onderbroken (door een schop, voorman, indringers), of de provider niet op de hoogte is van de storing, of een kortdurend probleem wordt verholpen voordat de installateur arriveert. Er zijn echter momenten waarop we het probleem vóór de gebruikers en voor de IT-services van de klant te weten komen, en de oplossing communiceren voordat ze zelfs maar beseffen dat er iets is gebeurd. Meestal doen dergelijke situaties zich 's nachts voor, wanneer de activiteit in klantbedrijven laag is.
Wie heeft het nodig en waarom?
In de regel heeft elk groot bedrijf zijn eigen IT-afdeling, die de details en taken duidelijk begrijpt. In middelgrote en grote bedrijven wordt het werk van "enikeevs" en netwerkingenieurs vaak uitbesteed. Het is gewoon voordelig en handig. Zo heeft de ene retailer zijn eigen heel coole IT'ers, maar die zijn nog lang niet bezig met het vervangen van routers en het opsporen van kabels.Wat doen wij
- We werken op verzoeken - tickets en paniekoproepen.
- Wij doen aan preventie.
- We volgen de aanbevelingen van hardwareleveranciers op, bijvoorbeeld over de voorwaarden van onderhoud.
- Wij sluiten aan op de monitoring van de klant en verwijderen gegevens van hem om te kunnen reizen bij incidenten.
De eerste manier - eenvoudige controles - is gewoon een machine die alle knooppunten op het netwerk pingt en ervoor zorgt dat ze correct reageren. Een dergelijke implementatie vereist helemaal geen wijzigingen of minimale cosmetische wijzigingen in het netwerk van de klant. In de regel installeren we Zabbix in een heel eenvoudig geval rechtstreeks voor onszelf in een van de datacenters (gelukkig hebben we er twee in het CROC-kantoor op Volochaevskaya). In een meer complexe, bijvoorbeeld als u uw eigen beveiligde netwerk gebruikt - naar een van de machines in het datacenter van de klant:

Zabbix kan ingewikkelder worden gebruikt, het heeft bijvoorbeeld agents die zijn geïnstalleerd op * nix en win-knooppunten en tonen systeembewaking, evenals externe controlemodus (met ondersteuning voor het SNMP-protocol). Desalniettemin, als een bedrijf iets soortgelijks nodig heeft, hebben ze al hun eigen monitoring, of wordt er gekozen voor een meer functioneel rijke oplossing. Dit is natuurlijk niet langer open source en het kost geld, maar zelfs een banaal nauwkeurige inventaris verslaat de kosten al met ongeveer een derde.
Wij doen dit ook, maar dit is het verhaal van collega's. Hier stuurden ze een paar screenshots van Infosim:


Ik ben een avatar-operator, dus ik zal je meer vertellen over mijn werk.
Hoe ziet een typisch incident eruit?
Voor ons staan schermen met de volgende algemene status:
Op deze faciliteit verzamelt Zabbix heel veel informatie voor ons: batchnummer, serienummer, CPU-belasting, apparaatbeschrijving, beschikbaarheid van de interface, enz. Allemaal Nodige informatie beschikbaar via deze interface.
Een gewoon incident begint meestal met het feit dat een van de kanalen die naar bijvoorbeeld de winkel van de klant leiden (waarvan hij 200-300 stuks in het hele land heeft) eraf valt. Retail is nu goed ontwikkeld, niet zoals zeven jaar geleden, dus de kassa zal blijven werken - er zijn twee kanalen.
We pakken de telefoons en bellen minimaal drie keer: naar de provider, de energiecentrale en de mensen ter plaatse (“Ja, we hebben hier fittingen geladen, iemands kabel is aangeraakt... Oh, die van jou? Nou, het is goed dat we hebben het gevonden").
Zonder monitoring gaan er in de regel uren of dagen voorbij voor een escalatie - dezelfde back-upkanalen worden niet altijd gecontroleerd. We weten het meteen en we vertrekken meteen. Als er naast pings nog aanvullende informatie is (bijvoorbeeld een model van een buggy stuk ijzer), vullen we de field engineer direct aan met de benodigde onderdelen. Verder al op zijn plaats.
De op één na meest voorkomende reguliere oproep is het uitvallen van een van de terminals voor gebruikers, bijvoorbeeld een DECT-telefoon of een wifi-router die het netwerk naar het kantoor heeft gedistribueerd. Hier leren we over het probleem van monitoring en krijgen we bijna onmiddellijk een telefoontje met details. Soms voegt de oproep niets nieuws toe ("Ik neem de telefoon op, er gaat iets niet"), soms is het erg handig ("We hebben hem van de tafel laten vallen"). Het is duidelijk dat dit in het tweede geval duidelijk geen regeleinde is.
Apparatuur in Moskou wordt gehaald uit onze hot reserve-magazijnen, we hebben er verschillende:

Klanten hebben meestal hun eigen voorraad met vaak defecte componenten - kantoorhandsets, voedingen, ventilatoren, enzovoort. Als u iets moet afleveren dat niet op zijn plaats is, niet naar Moskou, gaan we meestal zelf (vanwege installatie). Ik had bijvoorbeeld een nachttrip naar Nizhny Tagil.
Als de klant een eigen monitoring heeft, kan hij gegevens naar ons uploaden. Soms zetten we Zabbix in in polling-modus, alleen om transparantie en SLA-controle te garanderen (dit is ook gratis voor de klant). Wij plaatsen geen extra sensoren (dit wordt gedaan door collega's die voor continuïteit zorgen) productieprocessen), maar we kunnen er verbinding mee maken als de protocollen niet exotisch zijn.
Over het algemeen raken we de infrastructuur van de klant niet aan, we ondersteunen hem gewoon zoals hij is.
Uit ervaring kan ik zeggen dat de laatste tien klanten zijn overgestapt op externe ondersteuning vanwege het feit dat we qua kosten erg voorspelbaar zijn. Duidelijke budgettering, goed casemanagement, rapportage per aanvraag, SLA, equipment rapportages, preventief onderhoud. Idealiter zijn we natuurlijk voor de CIO van een klant zoals schoonmakers - we komen en doen het, alles is schoon, we leiden niet af.
Een ander ding dat het vermelden waard is, is dat in sommige grote bedrijven voorraad een echt probleem wordt, en soms worden we aangetrokken puur om het uit te voeren. Bovendien doen we de opslag van configuraties en het beheer ervan, wat handig is voor verschillende verhuizingen en herverbindingen. Maar nogmaals, in moeilijke gevallen ik ben het ook niet - we hebben een speciaal team dat datacenters vervoert.
En nog een belangrijk punt: onze afdeling houdt zich niet bezig met kritieke infrastructuur. Alles in de datacenters en alles in de bank-verzekering-operator, plus de retail-kernsystemen - dit is een X-team. Hier zijn de jongens.
Meer oefening
Veel moderne apparaten kunnen veel service-informatie geven. Met netwerkprinters is het bijvoorbeeld heel eenvoudig om het tonerniveau in de cartridge te controleren. Je kunt vooraf rekenen op de vervangingsperiode, plus een melding van 5-10% krijgen (als het kantoor ineens razend begint te typen niet in het standaardschema) - en direct een enikey sturen voordat de boekhouding in paniek raakt.Heel vaak worden jaarstatistieken van ons afgenomen, wat door hetzelfde monitoringsysteem plus ons wordt gedaan. In het geval van Zabbix is dit eenvoudige kostenplanning en begrijpen wat er mis is gegaan, en in het geval van Infosim is het ook materiaal voor het berekenen van de schaal voor een jaar, het laden van beheerders en allerlei andere dingen. Er is energieverbruik in de statistieken - het afgelopen jaar begon bijna iedereen hem te vragen, blijkbaar om interne kosten over afdelingen te spreiden.
Soms worden echte heroïsche reddingen verkregen. Dergelijke situaties zijn zeer zeldzaam, maar van wat ik me dit jaar herinner, zagen we rond 3 uur dat de temperatuur steeg tot 55 graden op de cisco-schakelaar. In de verre serverruimte waren er "domme" airconditioners zonder toezicht, en ze faalden. We belden onmiddellijk een koeltechnicus (niet de onze) en belden de dienstdoende beheerder van de klant. Hij voerde een aantal niet-kritieke diensten uit en zorgde ervoor dat de serverruimte niet werd neergeschoten totdat de man arriveerde met... mobiele airconditioner, en dan het personeel reparaties.
Polycoms en andere dure videoconferentieapparatuur houden het batterijniveau voor conferenties zeer goed in de gaten, wat ook belangrijk is.
Iedereen heeft monitoring en diagnostiek nodig. In de regel is het lang en moeilijk te implementeren zonder ervaring: systemen zijn ofwel extreem eenvoudig en vooraf geconfigureerd, of de grootte van een vliegdekschip en met een heleboel standaardrapporten. Aanscherpen met een dossier voor het bedrijf, de uitvoering van hun taken bedenken voor de interne IT-afdeling en de informatie tonen die ze het hardst nodig hebben, plus de hele historie up-to-date houden is een makkie als er geen implementatie-ervaring is. Bij het werken met monitoringsystemen kiezen we de gulden middenweg tussen gratis en topoplossingen - in de regel niet de meest populaire en "dikke" leveranciers, maar het probleem duidelijk oplossen.
Er was eens een nogal atypische behandeling. De klant moest de router aan enkele van zijn aparte afdelingen afstaan, en wel precies volgens de inventaris. De router had een module met het opgegeven serienummer. Toen de router zich begon voor te bereiden op de weg, bleek deze module te ontbreken. En niemand kan het vinden. Het probleem wordt enigszins verergerd door het feit dat de ingenieur die vorig jaar bij deze tak werkte al met pensioen is en met zijn kleinkinderen in een andere stad is gaan wonen. Ze namen contact met ons op en vroegen om te kijken. Gelukkig gaf de hardware rapporten over serienummers, en Infosim deed een inventarisatie, dus we vonden deze module in een paar minuten in de infrastructuur en beschreven de topologie. De voortvluchtige werd via de kabel opgespoord - hij was in een andere serverruimte in een kast. Uit de geschiedenis van de beweging bleek dat hij daar kwam na het uitvallen van een gelijkaardige module.

Een frame uit een speelfilm over Hottabych, die nauwkeurig de houding van de bevolking ten opzichte van camera's beschrijft
Veel camera-incidenten. Een keer vielen er 3 camera's tegelijk uit. Kabelbreuk in een van de secties. De installateur blies een nieuwe in de golving, twee van de drie kamers verrezen na een reeks van sjamanisme. En de derde niet. Bovendien is het helemaal niet duidelijk waar ze is. Ik verhoog de videostream - de laatste beelden vlak voor de val - 4 uur 's ochtends, drie mannen met sjaals op hun gezicht komen naar boven, iets helders beneden, de camera schudt veel, valt.
Zodra we de camera hebben opgesteld, die zich moet concentreren op de "hazen" die over het hek klimmen. Tijdens het rijden hebben we nagedacht over hoe we het punt zouden aanwijzen waar de indringer zou moeten verschijnen. Het kwam niet van pas - in de 15 minuten dat we er waren, kwamen 30 mensen het object binnen op het punt dat we nodig hadden. Rechtop tafel.
Zoals ik hierboven al een voorbeeld gaf, is het verhaal over het gesloopte pand geen grap. Zodra de link naar de apparatuur verdween. Op zijn plaats - er is geen paviljoen waar koper passeerde. Het paviljoen werd afgebroken, de kabel was weg. We zagen dat de router dood was. Het installatieprogramma arriveerde, begon te kijken - en de afstand tussen de knooppunten is een paar kilometer. Hij heeft een Vipnet-tester in zijn set, de standaard - hij ging van de ene connector, hij ging van de andere - hij ging op zoek. Meestal is het probleem direct zichtbaar.

De kabel volgen: dit is gegolfde optiek, een voortzetting van het verhaal vanaf de top van de post over de knoop. Hier was uiteindelijk, naast een volledig verbazingwekkende installatie, het probleem dat de kabel van de steunen was verwijderd. Hier klim alles en nog wat, en maak metalen constructies los. Ongeveer vijfduizendste vertegenwoordiger van het proletariaat brak de optiek.
Bij één faciliteit werden alle knooppunten ongeveer een keer per week uitgeschakeld. En op hetzelfde moment. We zijn al een tijdje op zoek naar een patroon. Het installatieprogramma vond het volgende:
- Het probleem doet zich altijd voor in de ploeg van dezelfde persoon.
- Hij verschilt van anderen doordat hij een zeer zware jas draagt.
- Achter een kleerhanger is een automaat gemonteerd.
- Iemand heeft lang geleden, in de prehistorie, de kap van de machine overgenomen.
- Wanneer deze kameraad naar de faciliteit komt, hangt hij zijn kleren op en zet zij de machines uit.
- Hij zet ze meteen weer aan.
Apparatuur werd 's nachts op één en hetzelfde tijdstip op hetzelfde tijdstip uitgeschakeld. Het bleek dat lokale ambachtslieden onze stroomvoorziening aansloten, een verlengsnoer tevoorschijn haalden en er een waterkoker en een elektrisch fornuis in stopten. Als deze apparaten tegelijkertijd werken, valt het hele paviljoen uit.
In een van de winkels van ons uitgestrekte land viel het hele netwerk constant uit met het sluiten van de ploeg. De installateur zag dat alle stroom naar de verlichtingslijn werd gebracht. Zodra de bovenverlichting van de hal (die veel energie verbruikt) in de winkel wordt uitgeschakeld, wordt alle netwerkapparatuur uitgeschakeld.
Er was een geval dat de conciërge de kabel onderbrak met een schop.
Vaak zien we gewoon koper liggen met een gescheurde golving. Eens, tussen twee werkplaatsen, stuurden lokale ambachtslieden eenvoudig een twisted pair-kabel zonder enige bescherming.
Buiten de bewoonde wereld klagen werknemers vaak dat ze worden blootgesteld aan 'onze' apparatuur. Schakelborden op sommige afgelegen locaties kunnen zich in dezelfde ruimte bevinden als de dienstdoende persoon. Zo kwamen we een paar keer schadelijke oma's tegen die ze aan het begin van de dienst uitschakelden.
Nog een verre stad hing een dweil aan de optiek. Ze braken de golf van de muur af en begonnen het te gebruiken als bevestigingsmiddelen voor apparatuur.

In dit geval zijn er duidelijk problemen met voeding.
Wat "grote" monitoring kan doen?
Ik zal het kort hebben over de mogelijkheden van serieuzere systemen, aan de hand van het voorbeeld van Infosim-installaties. Er zijn 4 oplossingen gecombineerd in één platform:- Foutbeheer - foutcontrole en gebeurteniscorrelatie.
- Prestatiebeheer.
- Inventarisatie en automatische topologiedetectie.
- Configuratiebeheer.
Afzonderlijk over de inventaris. De module toont niet alleen de lijst, maar bouwt ook de topologie zelf (tenminste in 95% van de gevallen probeert het en krijgt het goed). Het stelt u ook in staat om een up-to-date database van gebruikte en inactieve IT-apparatuur (netwerk, serverapparatuur, enz.) bij de hand te hebben, om verouderde apparatuur op tijd te vervangen (EOS / EOL). Over het algemeen is het handig voor grote bedrijven, maar in kleine bedrijven wordt dit grotendeels met de hand gedaan.
Voorbeelden van rapporten:
- Rapporten per type besturingssysteem, firmware, modellen en fabrikanten van apparatuur;
- Rapporteren over het aantal vrije poorten op elke switch in het netwerk / per geselecteerde fabrikant / per model / per subnet, enz.;
- Rapporteren over nieuw toegevoegde apparaten voor een bepaalde periode;
- Waarschuwing voor bijna lege toner printer;
- Evaluatie van de geschiktheid van het communicatiekanaal voor vertragings- en verliesgevoelig verkeer, actieve en passieve methoden;
- Het volgen van de kwaliteit en beschikbaarheid van communicatiekanalen (SLA) - genereren van rapporten over de kwaliteit van communicatiekanalen, uitgesplitst naar telecomoperators;
- De functionaliteit voor foutcontrole en gebeurteniscorrelatie wordt geïmplementeerd via het Root-Cause Analysis-mechanisme (zonder dat beheerders regels hoeven te schrijven) en het Alarm States Machine-mechanisme. Root-Cause Analysis is een analyse van de oorzaak van een ongeval op basis van de volgende procedures: 1. automatische detectie en lokalisatie van de storingslocatie; 2. het aantal calamiteiten terugbrengen tot één toets; 3. het identificeren van de gevolgen van een storing - wie en wat werd beïnvloed door de storing.

Stablenet - Embedded Agent (SNEA) - een computer die iets groter is dan een pakje sigaretten.
De installatie wordt uitgevoerd in geldautomaten of speciale netwerksegmenten waar toegankelijkheidstests vereist zijn. Met hun hulp worden belastingstests uitgevoerd.
Cloudbewaking
Een ander installatiemodel is SaaS in de cloud. Gemaakt voor één wereldwijde klant (een bedrijf met een continue productiecyclus met een geografische distributie van Europa tot Siberië).Tientallen faciliteiten, waaronder fabrieken en magazijnen Afgemaakte producten. Als hun kanalen vielen en hun ondersteuning werd uitgevoerd vanuit buitenlandse kantoren, begonnen de verzendingen vertragingen te veroorzaken, wat langs de golf tot verdere verliezen leidde. Al het werk is op verzoek gedaan en er is veel tijd gestoken in het onderzoeken van het incident.
We hebben speciaal voor hen monitoring opgezet en dit vervolgens op een aantal sites voltooid volgens de specifieke kenmerken van hun routering en hardware. Dit gebeurde allemaal in de CROC-cloud. Ze hebben het project zeer snel afgerond en opgeleverd.
Het resultaat is:
- Door de gedeeltelijke overdracht van het beheer van de netwerkinfrastructuur kon minimaal 50% worden geoptimaliseerd. Ontoegankelijkheid van apparatuur, kanaalbelasting, overschrijding van de door de fabrikant aanbevolen parameters: dit alles wordt binnen 5-10 minuten verholpen, binnen een uur gediagnosticeerd en geëlimineerd.
- Bij het ontvangen van een dienst uit de cloud, rekent de klant de kapitaalkosten voor het inzetten van zijn netwerkbewakingssysteem door in bedrijfskosten voor een abonnementsprijs voor onze dienst, waarvan op elk moment kan worden afgezien.
Het voordeel van de cloud is dat we in onze beslissing als het ware boven hun netwerk staan en objectiever kunnen kijken naar alles wat er gebeurt. Als we ons op dat moment in het netwerk bevonden, zouden we het beeld alleen tot aan het storingsknooppunt zien, en wat erachter gebeurt, zouden we niet meer weten.
Een paar laatste foto's
Dit is de "ochtendpuzzel":
En dit is de schat die we hebben gevonden:

Dit zat er in de kist:

En tot slot over het grappigste uitje. Ik ben ooit naar een winkel geweest.
Daar gebeurde het volgende: eerst begon het van het dak op het verlaagde plafond te druppelen. Toen vormde zich een meer in het verlaagde plafond, dat een van de tegels erodeerde en verbrijzelde. Als gevolg hiervan stroomde dit alles naar de elektricien. Toen weet ik niet precies wat er gebeurde, maar ergens in de kamer ernaast was er kortsluiting en ontstond er brand. Eerst werkten poederblussers, daarna arriveerden brandweerlieden en vulden alles met schuim. Ik kwam achter hen aan voor demontage. Ik moet zeggen dat de tsiska 2960 het na dit alles goed deed - ik kon de configuratie ophalen en het apparaat opsturen voor reparatie.
Nog een keer, tijdens het triggeren van het poedersysteem, was de Tsiskovsky 3745 in één blik bijna volledig gevuld met poeder. Alle interfaces waren vol - 2 x 48 poorten. Het moest ter plekke worden opgenomen. onthouden verleden geval, besloot om te proberen de configuraties "hot" te verwijderen, schudde het uit en maakte het zo goed mogelijk schoon. We zetten hem aan - eerst zei het apparaat "pff" en niesde naar ons met een grote stroom poeder. En toen rommelde het en stond op.
echo verzoek
Een echo-verzoek (ping) is een diagnostisch hulpmiddel dat wordt gebruikt om te achterhalen of een bepaalde host bereikbaar is op een IP-netwerk. Het echoverzoek wordt gedaan met behulp van het ICMP-protocol (Internet Control Message Protocol). Dit protocol wordt gebruikt om een echo-verzoek te sturen naar de host die wordt gecontroleerd. De host moet worden geconfigureerd om ICMP-pakketten te accepteren.
Inspectie
op echo verzoek
PRTG is een ping- en netwerkbewakingstool voor Windows. Het is compatibel met alle belangrijke Windows-systemen, inclusief Windows Server 2012 R2 en Windows 10.
PRTG is een krachtige tool voor het hele netwerk. Voor servers, routers, switches, uptime en cloudverbindingen houdt PRTG alles bij, zodat u het beheer uit handen kunt nemen. De ping-sensor, evenals SNMP-, NetFlow- en packet-sniffing-sensoren worden gebruikt om gedetailleerde informatie te verzamelen over de beschikbaarheid en werkbelasting van het netwerk.
PRTG heeft een aanpasbaar ingebouwd alarmsysteem dat u snel op de hoogte stelt van problemen. De ping-sensor is geconfigureerd als de primaire sensor voor netwerkapparaten. Als deze sensor uitvalt, worden alle andere sensoren op het apparaat in de slaapstand gezet. Dit betekent dat u in plaats van een stroom waarschuwingsberichten slechts één melding ontvangt.
Op elk moment, op uw verzoek, kunt u weergeven op het PRTG-dashboard Korte beoordeling. Je ziet direct of alles in orde is. Het dashboard kan worden aangepast aan uw specifieke behoeften. Buiten de werkplek, zoals bij het werken in een serverruimte, is toegang tot PRTG mogelijk via een smartphone-applicatie en mist u geen enkel evenement.
De initiële bewaking wordt direct tijdens de installatie geconfigureerd. Dit is mogelijk dankzij de auto-discovery-functie: PRTG pingt uw privé-IP-adressen en maakt automatisch sensoren voor beschikbare apparaten. Wanneer u PRTG voor de eerste keer opent, kunt u direct de beschikbaarheid van uw netwerk controleren.
Het PRTG-programma heeft een transparant licentiemodel. U kunt PRTG gratis testen. De ping-sensor en alarmfunctie zijn ook inbegrepen in de gratis versie en hebben een onbeperkte gebruiksduur. Als uw bedrijf of netwerk meer functies nodig heeft, kunt u uw licentie eenvoudig upgraden.
Schermafbeeldingen
Een korte introductie tot PRTG: Ping Monitoring



Je ping-sensoren in het volle zicht
- zelfs onderweg
PRTG is binnen enkele minuten geïnstalleerd en is compatibel met de meeste mobiele apparaten.
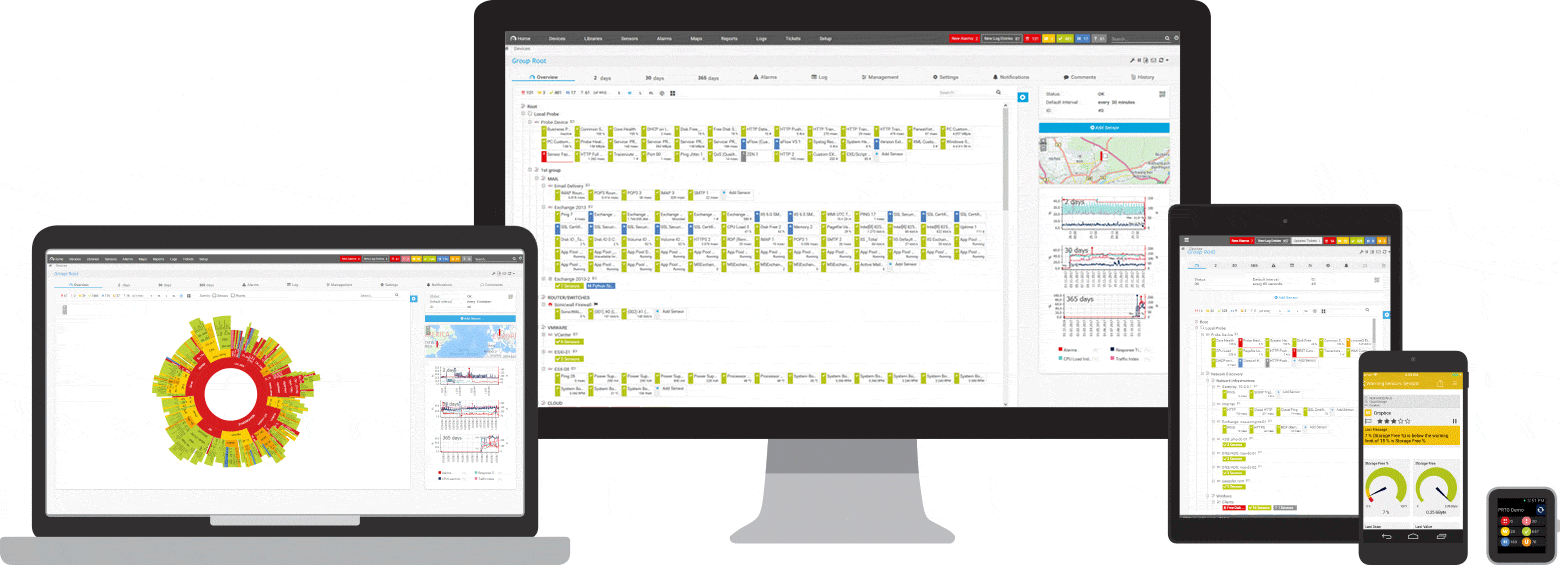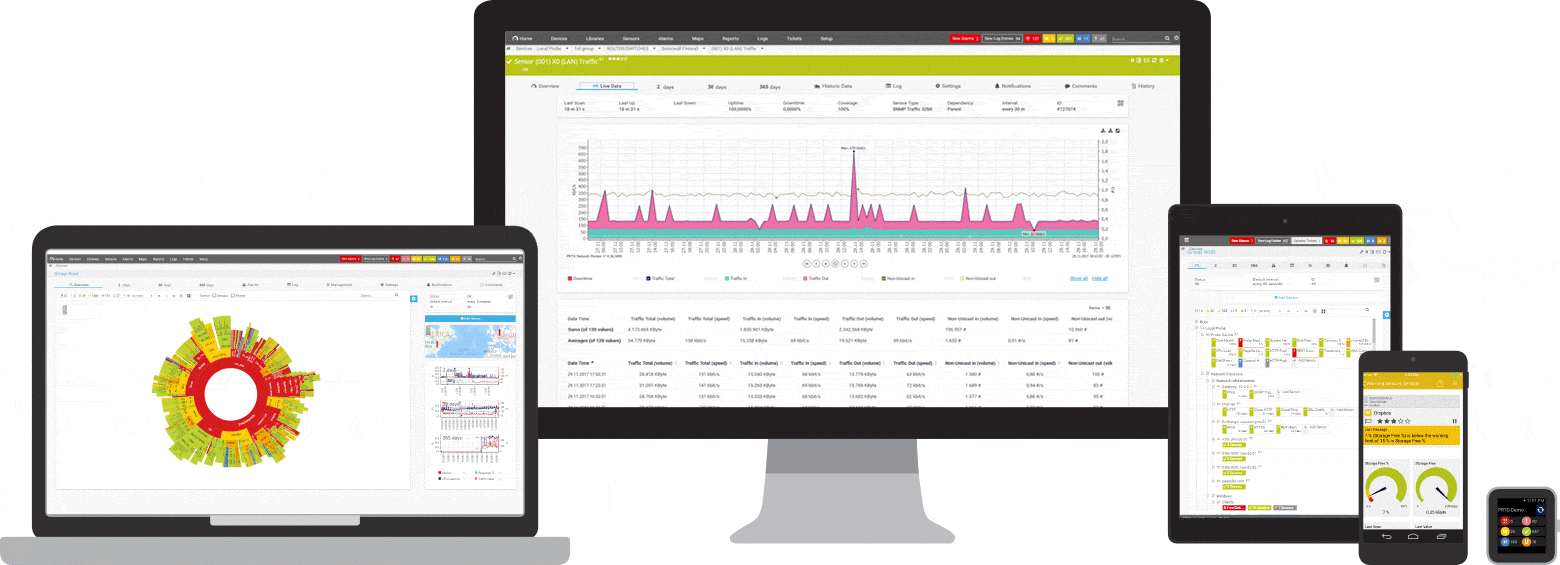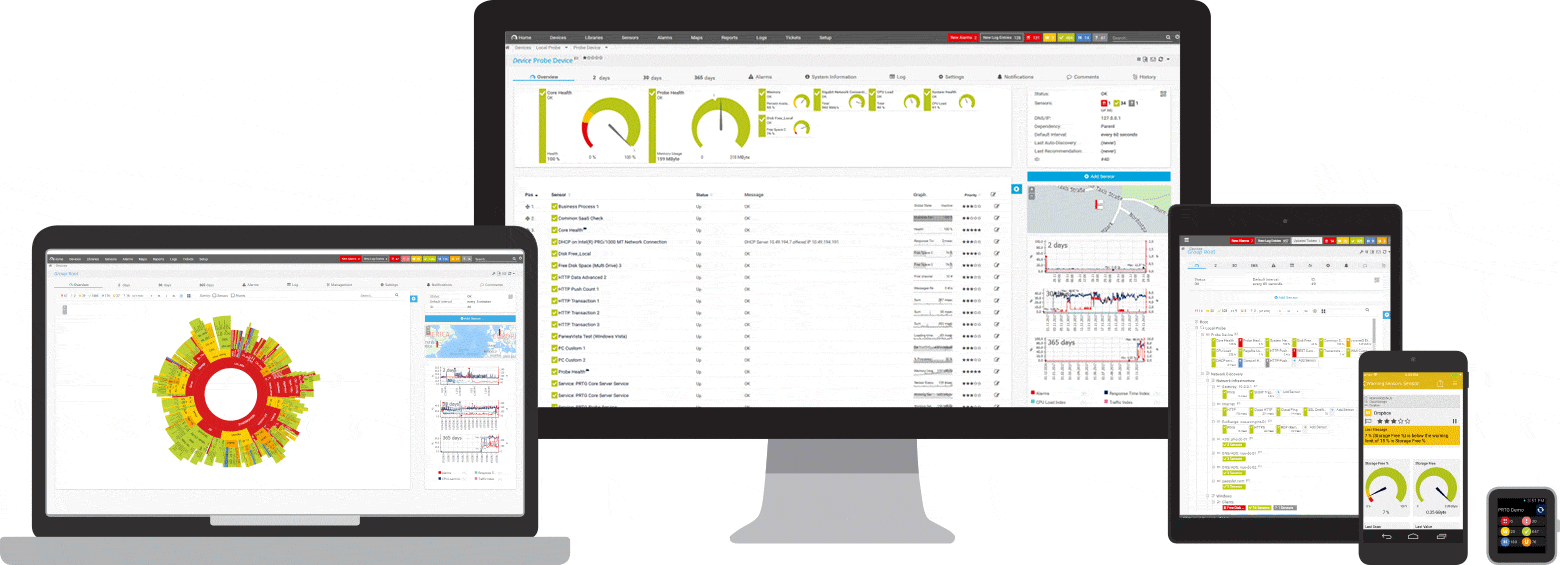
PRTG beheert deze en vele andere fabrikanten en toepassingen voor u
Drie PRTG-sensoren voor ping-bewaking
Sensor
echo verzoeken
uit de wolk
De Cloud Ping Sensor gebruikt de PRTG Cloud om de tijd te meten die nodig is om uw netwerk te pingen vanaf verschillende locaties over de hele wereld. Met deze sensor ziet u de beschikbaarheid van uw netwerk in Azië, Europa en Amerika. Vooral voor internationale bedrijven is deze indicator erg belangrijk. .
Door de PRTG-software aan te schaffen, krijgt u uitgebreide gratis ondersteuning. Het is onze taak om uw problemen zo snel mogelijk op te lossen! Speciaal hiervoor hebben we, samen met ander materiaal, trainingsvideo's en uitgebreide gids. We streven ernaar om alle supporttickets binnen 24 uur (weekdagen) te beantwoorden. In onze kennisbank vindt u antwoorden op veel vragen. De zoekopdracht 'ping monitoring' levert bijvoorbeeld 700 resultaten op. Een paar voorbeelden:
“Ik heb een ping-sensor nodig die alleen informatie verzamelt over de beschikbaarheid van het apparaat, zonder de status ervan te veranderen. Is dit mogelijk?"
"Kan ik een inverse echo-verzoeksensor bouwen?"

"Met PRTG zijn we veel comfortabeler omdat we weten dat onze systemen continu worden gecontroleerd."
Markus Puke, netwerkbeheerder, Schüchtermann-kliniek (Duitsland)
- Volledige versie van PRTG voor 30 dagen
- Na 30 dagen - gratis versie
- Voor uitgebreide versie - commerciële licentie

| Software voor netwerkbewaking - versie 19.2.50.2842 (15 mei 2019) | |
|
Hosting |
Cloudversie ook beschikbaar (PRTG in de cloud) |
Talen |
Engels, Duits, Russisch, Spaans, Frans, Portugees, Nederlands, Japans en Vereenvoudigd Chinees |
Prijzen |
Gratis tot 100 sensoren (prijzen) |
Uitgebreide bewaking |
Netwerkapparaten, bandbreedte, servers, applicaties, virtuele omgevingen, externe systemen, IoT en meer. |
Ondersteunde providers en applicaties |
Netwerk- en pingbewaking met PRTG: drie praktische casestudy's
200.000 beheerders over de hele wereld vertrouwen op het PRTG-programma. Deze beheerders kunnen uit verschillende branches komen, maar ze hebben allemaal één ding gemeen: de wens om de beschikbaarheid en prestaties van hun netwerken te waarborgen en te verbeteren. Drie gebruiksscenario's:

Zürich luchthaven
De luchthaven van Zürich is de grootste luchthaven van Zwitserland, dus het is vooral belangrijk dat al zijn elektronische systemen soepel werken. Om dit mogelijk te maken, implementeerde de IT-afdeling de PRTG Network Monitor-software van Paessler AG. Met ruim 4.500 sensoren zorgt deze tool ervoor dat problemen direct worden opgespoord en direct door het IT-team worden opgelost. In het verleden gebruikte de IT-afdeling verschillende monitoringprogramma's. Maar uiteindelijk kwam het management tot de conclusie dat dit software ongeschikt voor gespecialiseerde controle door operationeel en technisch personeel. Gebruiksvoorbeeld.

Bauhaus-universiteit, Weimar
De IT-systemen van de Bauhaus Universiteit in Weimar worden gebruikt door 5.000 studenten en 400 medewerkers. Voor het monitoren van het universitaire netwerk werd in het verleden gebruik gemaakt van een geïsoleerde oplossing op basis van Nagios. Het systeem was technisch verouderd en voldeed niet aan de behoeften van de IT-infrastructuur van de onderwijsinstelling. Upgrades van de infrastructuur zouden extreem duur zijn. In plaats daarvan wendde de universiteit zich tot nieuwe oplossingen voor netwerkmonitoring. De IT-managers wilden een uitgebreid softwareproduct dat gebruiksvriendelijk, eenvoudig te installeren en kosteneffectief was. Daarom kozen ze voor PRTG. Gebruiksvoorbeeld.

Openbare nutsbedrijven van de stad Frankenthal
Iets meer dan 200 medewerkers van de nutsbedrijven van de gemeente Frankenthal zijn verantwoordelijk voor de levering van elektriciteit, gas en water aan particulieren en organisaties. De organisatie is met al haar gebouwen ook afhankelijk van een lokaal gedistribueerde infrastructuur, die bestaat uit ongeveer 80 servers en 200 aangesloten apparaten. De IT-managers van Frankenthal waren op zoek naar betaalbare software om aan hun specifieke behoeften te voldoen. Eerst heeft IT een gratis proefversie van PRTG opgezet. De nutsbedrijven van Frankenthal gebruiken momenteel zo'n 1.500 sensoren om onder meer openbare zwembaden te bewaken. Gebruiksvoorbeeld.

Praktisch advies. Vertel me, Greg, heb je aanbevelingen voor het bewaken van pings?
“Pingback-sensoren zijn waarschijnlijk de belangrijkste elementen van netwerkmonitoring. Ze moeten correct worden geconfigureerd, vooral gezien uw verbindingen. Als je bijvoorbeeld een virtuele machine monitort, is het handig om een ping-sensor op de verbinding met zijn host te plaatsen. Als een knoop punt uitvalt, ontvangt u geen melding voor elke virtuele machine die ermee is verbonden. Bovendien kunnen ping-sensoren goede indicatoren zijn dat het netwerkpad naar de host of het internet goed werkt, vooral in scenario's met hoge beschikbaarheid of failover."
Greg Campion, systeembeheerder, PAESSLER AG
EMCO Ping-monitor. Gratis beheerdersassistent
Als uw infrastructuur maximaal 5 virtualisatiehosts heeft, kunt u de gratis versie gebruiken.
Ping Monitor: hulpprogramma voor het bewaken van de status van netwerkverbindingen (gratis voor 5 hosts)
Informatie:
Betrouwbare monitoringtool om automatisch de verbinding met het netwerk van hosts te controleren door een opdracht uit te voeren ping.
Wiki:
Ping is een hulpprogramma voor het testen van verbindingen op op TCP/IP gebaseerde netwerken, evenals de algemene naam voor het verzoek zelf.
Het hulpprogramma verzendt verzoeken (ICMP Echo-Request) van het ICMP-protocol naar de opgegeven host en legt binnenkomende antwoorden vast (ICMP Echo-Reply). De tijd tussen het verzenden van een verzoek en het ontvangen van een reactie (RTT, van de Engelse Round Trip Time) stelt u in staat om de retourvertragingen (RTT) langs de route en de frequentie van pakketverlies te bepalen, dat wil zeggen indirect de congestie op datakanalen en tussenliggende apparaten.
Het ping-programma is een van de belangrijkste diagnostische hulpmiddelen in TCP / IP-netwerken en is inbegrepen bij de levering van alle moderne netwerken besturingssystemen.
https://ru.wikipedia.org/wiki/Ping
Het programma bewaakt, door regelmatig ICMP-verzoeken te verzenden, netwerkverbindingen en stelt u op de hoogte van het gedetecteerde herstel / verlies van kanalen. EMCO Ping Monitor biedt verbindingsstatistieken, inclusief uptime, service-onderbrekingen, ping-storingen, enz.


Een robuuste ping-monitoringtool voor het automatisch controleren van de verbinding met netwerkhosts. Door regelmatig te pingen, worden netwerkverbindingen gecontroleerd en wordt u op de hoogte gebracht van gedetecteerde ups/downs. EMCO Ping Monitor biedt ook informatie over verbindingsstatistieken, inclusief uptime, uitval, mislukte pings, enz. U kunt de functionaliteit eenvoudig uitbreiden en EMCO Ping Monitor configureren om aangepaste opdrachten uit te voeren of toepassingen te starten wanneer verbindingen verloren gaan of hersteld worden.
Wat is EMCO Ping Monitor?
EMCO Ping Monitor kan in de 24/7-modus werken om de status van de verbinding van een of meerdere hosts te volgen. De applicatie analyseert ping-antwoorden om verbindingsstoringen te detecteren en verbindingsstatistieken te rapporteren. Het kan automatisch verbindingsstoringen detecteren en Windows Tray-ballonnen weergeven, geluiden afspelen en e-mailmeldingen verzenden. Het kan ook rapporten genereren en deze per e-mail verzenden of opslaan als PDF- of HTML-bestanden.
Met het programma kunt u informatie krijgen over de status van alle hosts, de gedetailleerde statistieken van een geselecteerde host bekijken en de prestaties van verschillende hosts vergelijken. Het programma slaat de verzamelde ping-gegevens op in de database, zodat u de statistieken voor een geselecteerde periode kunt controleren. De beschikbare informatie omvat min/max/gem. ping-tijd, ping-afwijking, lijst met verbindingsonderbrekingen, enz. Deze informatie kan worden weergegeven als rastergegevens en grafieken.
EMCO Ping-monitor: hoe werkt het?
EMCO Ping Monitor kan worden gebruikt om ping-monitoring uit te voeren van slechts een paar hosts of duizenden hosts. Alle hosts worden in realtime gemonitord door speciale werkthreads, zodat u realtime statistieken en meldingen van wijzigingen in de verbindingsstatus voor elke host kunt krijgen. Het programma stelt geen speciale vereisten voor hardware - je kunt een paar duizend hosts monitoren op een typische moderne pc.
Het programma gebruikt pings om verbindingsstoringen te detecteren. Als een paar pings in een raw niet werken, meldt het een storing en wordt u op de hoogte gebracht van het probleem. Wanneer de verbinding tot stand is gebracht en de pings echter beginnen te passeren, detecteert het programma het einde van de storing en stelt het u hiervan op de hoogte. U kunt uitval- en detectievoorwaarden aanpassen, evenals meldingen die door het programma worden gebruikt.
Vergelijk functies en selecteer de editie
Het programma is beschikbaar in drie edities met de verschillende functies.
Vergelijk edities
De gratis editie maakt het mogelijk om ping-monitoring uit te voeren van maximaal 5 hosts. Het staat geen specifieke configuratie voor hosts toe. Het wordt uitgevoerd als een Windows-programma, dus de bewaking wordt gestopt als u de gebruikersinterface sluit of uitlogt bij Windows.
Gratis voor persoonlijk en commercieel gebruik
Professionele Editie
Met de Professional-editie kunnen maximaal 250 hosts tegelijkertijd worden bewaakt. Elke host kan een aangepaste configuratie hebben, zoals een melding van e-mailontvangers of aangepaste acties die moeten worden uitgevoerd bij verbroken verbinding en herstelgebeurtenissen. Het wordt uitgevoerd als een Windows-service, dus de bewaking gaat door, zelfs als u de gebruikersinterface sluit of uitlogt bij Windows.
Bedrijfseditie
De Enterprise-editie heeft geen beperkingen op het aantal bewaakte hosts. Op een moderne pc is het mogelijk om 2500+ hosts te monitoren, afhankelijk van de hardwareconfiguratie.
Deze editie bevat alle beschikbare features en werkt als client/server. De server werkt als een Windows-service om ping-monitoring in de 24/7-modus te garanderen. De client is een Windows-programma dat verbinding kan maken met een server op een lokale pc of met een externe server via een LAN of internet. Meerdere clients kunnen verbinding maken met dezelfde server en gelijktijdig werken.
Deze editie bevat ook webrapporten, waarmee u de statistieken van hostbewaking op afstand in een webbrowser kunt bekijken.
De belangrijkste kenmerken van de EMCO Ping-monitor:
Ping-bewaking voor meerdere hosts
De applicatie kan meerdere hosts tegelijk monitoren. Met de gratis editie van de applicatie kunnen maximaal vijf hosts worden gecontroleerd; de Professional-editie heeft geen beperking voor het aantal bewaakte hosts. Monitoring van elke host werkt onafhankelijk van andere hosts. U kunt tienduizenden hosts monitoren vanaf een moderne pc.
Detectie van verbindingsonderbrekingen
De applicatie verzendt ICMP ping-echo-verzoeken en analyseert ping-echo-antwoorden om de verbindingsstatus in de 24/7-modus te bewaken. Als het vooraf ingestelde aantal pings achter elkaar mislukt, detecteert de toepassing een verbindingsstoring en wordt u op de hoogte gesteld van het probleem. De applicatie houdt alle storingen bij, zodat je kunt zien wanneer een host offline was.
Analyse verbindingskwaliteit
Wanneer de toepassing een bewaakte host pingt, worden gegevens over elke ping opgeslagen en verzameld, zodat u informatie kunt krijgen over de minimale, maximale en gemiddelde ping-responstijden en de ping-responsafwijking van het gemiddelde voor elke rapportageperiode. Daarmee kun je de kwaliteit van de netwerkverbinding inschatten.
Flexibele meldingen
Als u meldingen wilt ontvangen over verbinding verbroken, verbinding hersteld en andere gebeurtenissen die door de toepassing zijn gedetecteerd, kunt u de toepassing configureren om e-mailmeldingen te verzenden, geluiden af te spelen en Windows Tray-ballonnen weer te geven. De applicatie kan een enkele melding van elk type verzenden of meerdere keren herhalen.
Grafieken en rapporten
Alle statistische informatie die door de applicatie wordt verzameld, kan visueel worden weergegeven in grafieken. U kunt de ping- en uptimestatistieken voor een enkele host bekijken en de prestaties van meerdere hosts in grafieken vergelijken. De applicatie kan regelmatig automatisch rapporten in verschillende formaten genereren om de hoststatistieken weer te geven.
Aangepaste acties
U kunt de applicatie integreren met externe software door externe scripts of uitvoerbare bestanden uit te voeren wanneer verbindingen verloren gaan of hersteld worden of in het geval van andere gebeurtenissen. U kunt de toepassing bijvoorbeeld configureren om een externe opdrachtregeltool uit te voeren om sms-meldingen te verzenden over eventuele wijzigingen in de hoststatussen.
Aan het uiterlijk van deze optiek, die door het bos naar de verzamelaar gaat, kunnen we concluderen dat de installateur de techniek niet een beetje heeft gevolgd. De berg op de foto suggereert ook dat hij waarschijnlijk een zeeman is - een mariene knoop.
Ik zit in het fysieke netwerkgezondheidsteam, met andere woorden, technische ondersteuning, die ervoor zorgt dat de lampjes op de routers knipperen zoals het hoort. Wij hebben onder onze hoede diverse grote bedrijven met infrastructuur door het hele land. We klimmen niet in hun bedrijf, het is onze taak om ervoor te zorgen dat het netwerk op fysiek niveau werkt en dat het verkeer verloopt zoals het hoort.
De algemene betekenis van het werk is constant pollen van nodes, telemetrie verwijderen, testruns (bijvoorbeeld instellingen controleren om kwetsbaarheden te vinden), gezondheid verzekeren, applicaties monitoren, verkeer. Soms voorraden en andere perversies.
Ik zal je vertellen hoe het is georganiseerd en een paar verhalen van de reizen.
Zoals meestal het geval is
Ons team zit in een kantoor in Moskou en neemt netwerktelemetrie. Eigenlijk zijn dit constante pings van knooppunten, evenals het ontvangen van monitoringgegevens als de hardware slim is. De meest voorkomende situatie is dat de ping meerdere keren achter elkaar niet wordt doorgegeven. In 80% van de gevallen bij een winkelketen blijkt dit bijvoorbeeld een stroomstoring te zijn, dus bij het zien van dit plaatje doen we het volgende:- Eerst bellen we de provider over ongevallen
- Dan - naar de energiecentrale over de sluiting
- Dan proberen we een verbinding tot stand te brengen met iemand op de faciliteit (dit is niet altijd mogelijk, bijvoorbeeld om 02.00 uur)
- En ten slotte, als het bovenstaande niet binnen 5-10 minuten heeft geholpen, gaan we weg of sturen we een "avatar" - een contractingenieur die ergens in Izhevsk of Vladivostok zit, als het probleem daar is.
- We houden constant contact met de "avatar" en "leiden" hem door de infrastructuur - we hebben sensoren en servicehandleidingen, hij heeft een tang.
- Dan stuurt de monteur ons een rapport met een foto over wat het was.
De dialoog gaat soms als volgt:
- Dus de verbinding is verbroken tussen gebouw nummer 4 en 5. Controleer de router in de vijfde.
- Bestelling, inbegrepen. Er is geen verbinding.
- Ok, ga langs de kabel naar het vierde gebouw, daar is nog een knoop.
-... Opa!
- Wat er is gebeurd?
- Hier is het 4e huis gesloopt.
- Wat??
- Ik voeg een foto bij het rapport. Ik kan het huis niet herstellen in SLA.
Maar vaker blijkt het toch een pauze te vinden en het kanaal te herstellen.
Ongeveer 60% van de ritten is "in de melk", omdat ofwel de stroomtoevoer wordt onderbroken (door een schop, voorman, indringers), of de provider niet op de hoogte is van de storing, of een kortdurend probleem wordt verholpen voordat de installateur arriveert. Er zijn echter momenten waarop we het probleem vóór de gebruikers en voor de IT-services van de klant te weten komen, en de oplossing communiceren voordat ze zelfs maar beseffen dat er iets is gebeurd. Meestal doen dergelijke situaties zich 's nachts voor, wanneer de activiteit in klantbedrijven laag is.
Wie heeft het nodig en waarom?
In de regel heeft elk groot bedrijf zijn eigen IT-afdeling, die de details en taken duidelijk begrijpt. In middelgrote en grote bedrijven wordt het werk van "enikeevs" en netwerkingenieurs vaak uitbesteed. Het is gewoon voordelig en handig. Zo heeft de ene retailer zijn eigen heel coole IT'ers, maar die zijn nog lang niet bezig met het vervangen van routers en het opsporen van kabels.Wat doen wij
- We werken op verzoeken - tickets en paniekoproepen.
- Wij doen aan preventie.
- We volgen de aanbevelingen van hardwareleveranciers op, bijvoorbeeld over de voorwaarden van onderhoud.
- Wij sluiten aan op de monitoring van de klant en verwijderen gegevens van hem om te kunnen reizen bij incidenten.
De eerste manier - eenvoudige controles - is gewoon een machine die alle knooppunten op het netwerk pingt en ervoor zorgt dat ze correct reageren. Een dergelijke implementatie vereist helemaal geen wijzigingen of minimale cosmetische wijzigingen in het netwerk van de klant. In de regel installeren we Zabbix in een heel eenvoudig geval rechtstreeks voor onszelf in een van de datacenters (gelukkig hebben we er twee in het CROC-kantoor op Volochaevskaya). In een meer complexe, bijvoorbeeld als u uw eigen beveiligde netwerk gebruikt - naar een van de machines in het datacenter van de klant:
Zabbix kan ingewikkelder worden gebruikt, het heeft bijvoorbeeld agents die zijn geïnstalleerd op * nix en win-knooppunten en tonen systeembewaking, evenals externe controlemodus (met ondersteuning voor het SNMP-protocol). Desalniettemin, als een bedrijf iets soortgelijks nodig heeft, hebben ze al hun eigen monitoring, of wordt er gekozen voor een meer functioneel rijke oplossing. Dit is natuurlijk niet langer open source en het kost geld, maar zelfs een banaal nauwkeurige inventaris verslaat de kosten al met ongeveer een derde.
Wij doen dit ook, maar dit is het verhaal van collega's. Hier stuurden ze een paar screenshots van Infosim:
Ik ben een avatar-operator, dus ik zal je meer vertellen over mijn werk.
Hoe ziet een typisch incident eruit?
Voor ons staan schermen met de volgende algemene status:
Over dit object verzamelt Zabbix heel wat informatie voor ons: batchnummer, serienummer, CPU-gebruik, apparaatbeschrijving, beschikbaarheid van interfaces, enz. Alle benodigde informatie is beschikbaar via deze interface.
Een gewoon incident begint meestal met het feit dat een van de kanalen die naar bijvoorbeeld de winkel van de klant leiden (waarvan hij 200-300 stuks in het hele land heeft) eraf valt. Retail is nu goed ontwikkeld, niet zoals zeven jaar geleden, dus de kassa zal blijven werken - er zijn twee kanalen.
We pakken de telefoons en bellen minimaal drie keer: naar de provider, de energiecentrale en de mensen ter plaatse (“Ja, we hebben hier fittingen geladen, iemands kabel is aangeraakt... Oh, die van jou? Nou, het is goed dat we hebben het gevonden").
Zonder monitoring gaan er in de regel uren of dagen voorbij voor een escalatie - dezelfde back-upkanalen worden niet altijd gecontroleerd. We weten het meteen en we vertrekken meteen. Als er naast pings nog aanvullende informatie is (bijvoorbeeld een model van een buggy stuk ijzer), vullen we de field engineer direct aan met de benodigde onderdelen. Verder al op zijn plaats.
De op één na meest voorkomende reguliere oproep is het uitvallen van een van de terminals voor gebruikers, bijvoorbeeld een DECT-telefoon of een wifi-router die het netwerk naar het kantoor heeft gedistribueerd. Hier leren we over het probleem van monitoring en krijgen we bijna onmiddellijk een telefoontje met details. Soms voegt de oproep niets nieuws toe ("Ik neem de telefoon op, er gaat iets niet"), soms is het erg handig ("We hebben hem van de tafel laten vallen"). Het is duidelijk dat dit in het tweede geval duidelijk geen regeleinde is.
Apparatuur in Moskou wordt gehaald uit onze hot reserve-magazijnen, we hebben er verschillende:
Klanten hebben meestal hun eigen voorraad met vaak defecte componenten - kantoorhandsets, voedingen, ventilatoren, enzovoort. Als u iets moet afleveren dat niet op zijn plaats is, niet naar Moskou, gaan we meestal zelf (vanwege installatie). Ik had bijvoorbeeld een nachttrip naar Nizhny Tagil.
Als de klant een eigen monitoring heeft, kan hij gegevens naar ons uploaden. Soms zetten we Zabbix in in polling-modus, alleen om transparantie en SLA-controle te garanderen (dit is ook gratis voor de klant). We installeren geen extra sensoren (dit wordt gedaan door collega's die de continuïteit van productieprocessen waarborgen), maar we kunnen hierop aansluiten als de protocollen niet exotisch zijn.
Over het algemeen raken we de infrastructuur van de klant niet aan, we ondersteunen hem gewoon zoals hij is.
Uit ervaring kan ik zeggen dat de laatste tien klanten zijn overgestapt op externe ondersteuning vanwege het feit dat we qua kosten erg voorspelbaar zijn. Duidelijke budgettering, goed casemanagement, rapportage per aanvraag, SLA, equipment rapportages, preventief onderhoud. Idealiter zijn we natuurlijk voor de CIO van een klant zoals schoonmakers - we komen en doen het, alles is schoon, we leiden niet af.
Een ander ding dat het vermelden waard is, is dat in sommige grote bedrijven voorraad een echt probleem wordt, en soms worden we aangetrokken puur om het uit te voeren. Bovendien doen we de opslag van configuraties en het beheer ervan, wat handig is voor verschillende verhuizingen en herverbindingen. Maar nogmaals, in moeilijke gevallen ben ik dit ook niet - we hebben een speciale die datacenters vervoert.
En nog een belangrijk punt: onze afdeling houdt zich niet bezig met kritieke infrastructuur. Alles in de datacenters en alles in de bank-verzekering-operator, plus de retail-kernsystemen - dit is een X-team. deze jongens.
Meer oefening
Veel moderne apparaten kunnen veel service-informatie geven. Met netwerkprinters is het bijvoorbeeld heel eenvoudig om het tonerniveau in de cartridge te controleren. Je kunt vooraf rekenen op de vervangingsperiode, plus een melding van 5-10% krijgen (als het kantoor ineens razend begint te typen niet in het standaardschema) - en direct een enikey sturen voordat de boekhouding in paniek raakt.Heel vaak worden jaarstatistieken van ons afgenomen, wat door hetzelfde monitoringsysteem plus ons wordt gedaan. In het geval van Zabbix is dit eenvoudige kostenplanning en begrijpen wat er mis is gegaan, en in het geval van Infosim is het ook materiaal voor het berekenen van de schaal voor een jaar, het laden van beheerders en allerlei andere dingen. Er is energieverbruik in de statistieken - het afgelopen jaar begon bijna iedereen hem te vragen, blijkbaar om interne kosten over afdelingen te spreiden.
Soms worden echte heroïsche reddingen verkregen. Dergelijke situaties zijn zeer zeldzaam, maar van wat ik me dit jaar herinner, zagen we rond 3 uur dat de temperatuur steeg tot 55 graden op de cisco-schakelaar. In de verre serverruimte waren er "domme" airconditioners zonder toezicht, en ze faalden. We belden onmiddellijk een koeltechnicus (niet de onze) en belden de dienstdoende beheerder van de klant. Hij voerde een aantal niet-kritieke diensten uit en zorgde ervoor dat de serverruimte niet werd neergeschoten totdat de man met een mobiele airconditioner arriveerde, en toen werden de gewone gerepareerd.
Polycoms en andere dure videoconferentieapparatuur houden het batterijniveau voor conferenties zeer goed in de gaten, wat ook belangrijk is.
Iedereen heeft monitoring en diagnostiek nodig. In de regel is het lang en moeilijk te implementeren zonder ervaring: systemen zijn ofwel extreem eenvoudig en vooraf geconfigureerd, of de grootte van een vliegdekschip en met een heleboel standaardrapporten. Aanscherpen met een dossier voor het bedrijf, de uitvoering van hun taken bedenken voor de interne IT-afdeling en de informatie tonen die ze het hardst nodig hebben, plus de hele historie up-to-date houden is een makkie als er geen implementatie-ervaring is. Bij het werken met monitoringsystemen kiezen we de gulden middenweg tussen gratis en topoplossingen - in de regel niet de meest populaire en "dikke" leveranciers, maar het probleem duidelijk oplossen.
Er was eens een nogal atypische behandeling. De klant moest de router aan enkele van zijn aparte afdelingen afstaan, en wel precies volgens de inventaris. De router had een module met het opgegeven serienummer. Toen de router zich begon voor te bereiden op de weg, bleek deze module te ontbreken. En niemand kan het vinden. Het probleem wordt enigszins verergerd door het feit dat de ingenieur die vorig jaar bij deze tak werkte al met pensioen is en met zijn kleinkinderen in een andere stad is gaan wonen. Ze namen contact met ons op en vroegen om te kijken. Gelukkig gaf de hardware rapporten over serienummers, en Infosim deed een inventarisatie, dus we vonden deze module in een paar minuten in de infrastructuur en beschreven de topologie. De voortvluchtige werd via de kabel opgespoord - hij was in een andere serverruimte in een kast. Uit de geschiedenis van de beweging bleek dat hij daar kwam na het uitvallen van een gelijkaardige module.
Een frame uit een speelfilm over Hottabych, die nauwkeurig de houding van de bevolking ten opzichte van camera's beschrijft
Veel camera-incidenten. Een keer vielen er 3 camera's tegelijk uit. Kabelbreuk in een van de secties. De installateur blies een nieuwe in de golving, twee van de drie kamers verrezen na een reeks van sjamanisme. En de derde niet. Bovendien is het helemaal niet duidelijk waar ze is. Ik verhoog de videostream - de laatste beelden vlak voor de val - 4 uur 's ochtends, drie mannen met sjaals op hun gezicht komen naar boven, iets helders beneden, de camera schudt veel, valt.
Zodra we de camera hebben opgesteld, die zich moet concentreren op de "hazen" die over het hek klimmen. Tijdens het rijden hebben we nagedacht over hoe we het punt zouden aanwijzen waar de indringer zou moeten verschijnen. Het kwam niet van pas - in de 15 minuten dat we er waren, kwamen 30 mensen het object binnen op het punt dat we nodig hadden. Rechtop tafel.
Zoals ik hierboven al een voorbeeld gaf, is het verhaal over het gesloopte pand geen grap. Zodra de link naar de apparatuur verdween. Op zijn plaats - er is geen paviljoen waar koper passeerde. Het paviljoen werd afgebroken, de kabel was weg. We zagen dat de router dood was. Het installatieprogramma arriveerde, begon te kijken - en de afstand tussen de knooppunten is een paar kilometer. Hij heeft een Vipnet-tester in zijn set, de standaard - hij ging van de ene connector, hij ging van de andere - hij ging op zoek. Meestal is het probleem direct zichtbaar.
De kabel volgen: dit is gegolfde optiek, een voortzetting van het verhaal vanaf de top van de post over de knoop. Hier was uiteindelijk, naast een volledig verbazingwekkende installatie, het probleem dat de kabel van de steunen was verwijderd. Hier klim alles en nog wat, en maak metalen constructies los. Ongeveer vijfduizendste vertegenwoordiger van het proletariaat brak de optiek.
Bij één faciliteit werden alle knooppunten ongeveer een keer per week uitgeschakeld. En op hetzelfde moment. We zijn al een tijdje op zoek naar een patroon. Het installatieprogramma vond het volgende:
- Het probleem doet zich altijd voor in de ploeg van dezelfde persoon.
- Hij verschilt van anderen doordat hij een zeer zware jas draagt.
- Achter een kleerhanger is een automaat gemonteerd.
- Iemand heeft lang geleden, in de prehistorie, de kap van de machine overgenomen.
- Wanneer deze kameraad naar de faciliteit komt, hangt hij zijn kleren op en zet zij de machines uit.
- Hij zet ze meteen weer aan.
Apparatuur werd 's nachts op één en hetzelfde tijdstip op hetzelfde tijdstip uitgeschakeld. Het bleek dat lokale ambachtslieden onze stroomvoorziening aansloten, een verlengsnoer tevoorschijn haalden en er een waterkoker en een elektrisch fornuis in stopten. Als deze apparaten tegelijkertijd werken, valt het hele paviljoen uit.
In een van de winkels van ons uitgestrekte land viel het hele netwerk constant uit met het sluiten van de ploeg. De installateur zag dat alle stroom naar de verlichtingslijn werd gebracht. Zodra de bovenverlichting van de hal (die veel energie verbruikt) in de winkel wordt uitgeschakeld, wordt alle netwerkapparatuur uitgeschakeld.
Er was een geval dat de conciërge de kabel onderbrak met een schop.
Vaak zien we gewoon koper liggen met een gescheurde golving. Eens, tussen twee werkplaatsen, stuurden lokale ambachtslieden eenvoudig een twisted pair-kabel zonder enige bescherming.
Buiten de bewoonde wereld klagen werknemers vaak dat ze worden blootgesteld aan 'onze' apparatuur. Schakelborden op sommige afgelegen locaties kunnen zich in dezelfde ruimte bevinden als de dienstdoende persoon. Zo kwamen we een paar keer schadelijke oma's tegen die ze aan het begin van de dienst uitschakelden.
Nog een verre stad hing een dweil aan de optiek. Ze braken de golf van de muur af en begonnen het te gebruiken als bevestigingsmiddelen voor apparatuur.
In dit geval zijn er duidelijk problemen met voeding.
Wat "grote" monitoring kan doen?
Ik zal het kort hebben over de mogelijkheden van serieuzere systemen, aan de hand van het voorbeeld van Infosim-installaties. Er zijn 4 oplossingen gecombineerd in één platform:- Foutbeheer - foutcontrole en gebeurteniscorrelatie.
- Prestatiebeheer.
- Inventarisatie en automatische topologiedetectie.
- Configuratiebeheer.
Afzonderlijk over de inventaris. De module toont niet alleen de lijst, maar bouwt ook de topologie zelf (tenminste in 95% van de gevallen probeert het en krijgt het goed). Het stelt u ook in staat om een up-to-date database van gebruikte en inactieve IT-apparatuur (netwerk, serverapparatuur, enz.) bij de hand te hebben, om verouderde apparatuur op tijd te vervangen (EOS / EOL). Over het algemeen is het handig voor grote bedrijven, maar in kleine bedrijven wordt dit grotendeels met de hand gedaan.
Voorbeelden van rapporten:
- Rapporten per type besturingssysteem, firmware, modellen en fabrikanten van apparatuur;
- Rapporteren over het aantal vrije poorten op elke switch in het netwerk / per geselecteerde fabrikant / per model / per subnet, enz.;
- Rapporteren over nieuw toegevoegde apparaten voor een bepaalde periode;
- Waarschuwing voor bijna lege toner printer;
- Evaluatie van de geschiktheid van het communicatiekanaal voor vertragings- en verliesgevoelig verkeer, actieve en passieve methoden;
- Het volgen van de kwaliteit en beschikbaarheid van communicatiekanalen (SLA) - genereren van rapporten over de kwaliteit van communicatiekanalen, uitgesplitst naar telecomoperators;
- De functionaliteit voor foutcontrole en gebeurteniscorrelatie wordt geïmplementeerd via het Root-Cause Analysis-mechanisme (zonder dat beheerders regels hoeven te schrijven) en het Alarm States Machine-mechanisme. Root-Cause Analysis is een analyse van de oorzaak van een ongeval op basis van de volgende procedures: 1. automatische detectie en lokalisatie van de storingslocatie; 2. het aantal calamiteiten terugbrengen tot één toets; 3. het identificeren van de gevolgen van een storing - wie en wat werd beïnvloed door de storing.
Stablenet - Embedded Agent (SNEA) - een computer die iets groter is dan een pakje sigaretten.
De installatie wordt uitgevoerd in geldautomaten of speciale netwerksegmenten waar toegankelijkheidstests vereist zijn. Met hun hulp worden belastingstests uitgevoerd.
Cloudbewaking
Een ander installatiemodel is SaaS in de cloud. Gemaakt voor één wereldwijde klant (een bedrijf met een continue productiecyclus met een geografische distributie van Europa tot Siberië).Tientallen faciliteiten, waaronder fabrieken en magazijnen voor afgewerkte producten. Als hun kanalen vielen en hun ondersteuning werd uitgevoerd vanuit buitenlandse kantoren, begonnen de verzendingen vertragingen te veroorzaken, wat langs de golf tot verdere verliezen leidde. Al het werk is op verzoek gedaan en er is veel tijd gestoken in het onderzoeken van het incident.
We hebben speciaal voor hen monitoring opgezet en dit vervolgens op een aantal sites voltooid volgens de specifieke kenmerken van hun routering en hardware. Dit gebeurde allemaal in de CROC-cloud. Ze hebben het project zeer snel afgerond en opgeleverd.
Het resultaat is:
- Door de gedeeltelijke overdracht van het beheer van de netwerkinfrastructuur kon minimaal 50% worden geoptimaliseerd. Ontoegankelijkheid van apparatuur, kanaalbelasting, overschrijding van de door de fabrikant aanbevolen parameters: dit alles wordt binnen 5-10 minuten verholpen, binnen een uur gediagnosticeerd en geëlimineerd.
- Bij het ontvangen van een dienst uit de cloud, rekent de klant de kapitaalkosten voor het inzetten van zijn netwerkbewakingssysteem door in bedrijfskosten voor een abonnementsprijs voor onze dienst, waarvan op elk moment kan worden afgezien.
Het voordeel van de cloud is dat we in onze beslissing als het ware boven hun netwerk staan en objectiever kunnen kijken naar alles wat er gebeurt. Als we ons op dat moment in het netwerk bevonden, zouden we het beeld alleen tot aan het storingsknooppunt zien, en wat erachter gebeurt, zouden we niet meer weten.
Een paar laatste foto's
Dit is de "ochtendpuzzel":
En dit is de schat die we hebben gevonden:
Dit zat er in de kist:
En tot slot over het grappigste uitje. Ik ben ooit naar een winkel geweest.
Daar gebeurde het volgende: eerst begon het van het dak op het verlaagde plafond te druppelen. Toen vormde zich een meer in het verlaagde plafond, dat een van de tegels erodeerde en verbrijzelde. Als gevolg hiervan stroomde dit alles naar de elektricien. Toen weet ik niet precies wat er gebeurde, maar ergens in de kamer ernaast was er kortsluiting en ontstond er brand. Eerst werkten poederblussers, daarna arriveerden brandweerlieden en vulden alles met schuim. Ik kwam achter hen aan voor demontage. Ik moet zeggen dat de tsiska 2960 het na dit alles goed deed - ik kon de configuratie ophalen en het apparaat opsturen voor reparatie.
Nog een keer, tijdens het triggeren van het poedersysteem, was de Tsiskovsky 3745 in één blik bijna volledig gevuld met poeder. Alle interfaces waren vol - 2 x 48 poorten. Het moest ter plekke worden opgenomen. We herinnerden ons het laatste geval, besloten om te proberen de configuraties "hot" te verwijderen, schudden het eruit en maakten het zo goed mogelijk schoon. We zetten hem aan - eerst zei het apparaat "pff" en niesde naar ons met een grote stroom poeder. En toen rommelde het en stond op.



