Program for å spore ping i spill. Nettverksovervåking: hvordan vi sørger for at alle noder fungerer for store selskaper
Ved utseendet til denne optikken, som går gjennom skogen til samleren, kan vi konkludere med at installatøren ikke fulgte teknologien litt. Festet på bildet antyder også at han sannsynligvis er en sjømann - en marineknute.
Jeg er på det fysiske nettverkshelseteamet, med andre ord teknisk støtte, som har ansvar for at lysene på ruterne blinker som de skal. Vi har under vingen ulike store selskaper med infrastruktur over hele landet. Vi klatrer ikke inne i deres virksomhet, vår oppgave er å sørge for at nettet fungerer på det fysiske nivået og trafikken går som den skal.
Den generelle betydningen av arbeidet er konstant polling av noder, fjerning av telemetri, testkjøringer (for eksempel sjekke innstillinger for å finne sårbarheter), sikring av helse, overvåking av applikasjoner, trafikk. Noen ganger varelager og andre perversjoner.
Jeg skal fortelle om hvordan det er organisert og et par historier fra turene.
Som det vanligvis er
Teamet vårt sitter på et kontor i Moskva og tar nettverkstelemetri. Faktisk er dette konstante ping av noder, samt mottak av overvåkingsdata hvis maskinvaren er smart. Den vanligste situasjonen er at ping ikke passerer flere ganger på rad. I 80 % av tilfellene for en forhandlerkjede, for eksempel, viser dette seg å være et strømbrudd, så vi, ser dette bildet, gjør følgende:- Først ringer vi leverandøren om ulykker
- Så - til kraftverket om nedstengningen
- Deretter prøver vi å etablere en forbindelse med noen på anlegget (dette er ikke alltid mulig, for eksempel kl. 02.00)
- Og til slutt, hvis det ovennevnte ikke hjalp på 5-10 minutter, forlater vi oss selv eller sender en "avatar" - en kontraktsingeniør som sitter et sted i Izhevsk eller Vladivostok, hvis problemet er der.
- Vi holder konstant kontakt med «avataren» og «leder» den gjennom infrastrukturen – vi har sensorer og servicemanualer, han har tang.
- Så sender ingeniøren oss en rapport med bilde om hva det var.
Dialogen går noen ganger slik:
– Så, forbindelsen er tapt mellom bygg nummer 4 og 5. Sjekk ruteren i den femte.
- Bestilling, inkludert. Det er ingen sammenheng.
- Ok, gå langs kabelen til den fjerde bygningen, det er en annen node.
-... Oppa!
- Hva skjedde?
– Her ble det 4. huset revet.
- Hva??
– Jeg legger ved et bilde til rapporten. Jeg kan ikke restaurere huset i SLA.

Men oftere viser det seg likevel å finne en pause og gjenopprette kanalen.
Omtrent 60 % av turene er "i melken", fordi enten strømforsyningen blir avbrutt (av en spade, arbeidsleder, inntrengere), eller at leverandøren ikke vet om feilen, eller et kortsiktig problem er eliminert før installatøren kommer. Men det er tider hvor vi finner ut av problemet før brukerne og før kundens IT-tjenester, og kommuniserer løsningen før de i det hele tatt skjønner at noe har skjedd. Oftest oppstår slike situasjoner om natten, når aktiviteten i kundebedriftene er lav.
Hvem trenger det og hvorfor
Som regel har ethvert stort selskap sin egen IT-avdeling, som tydelig forstår detaljene og oppgavene. I mellomstore og store virksomheter er arbeidet til «enikeevs» og nettverksingeniører ofte satt ut. Det er bare nyttig og praktisk. For eksempel har én forhandler sine egne veldig kule IT-folk, men de er langt fra å bytte ut rutere og spore opp kabler.Hva gjør vi
- Vi jobber med forespørsler - billetter og panikkanrop.
- Vi gjør forebygging.
- Vi følger anbefalingene fra maskinvareleverandører, for eksempel om vilkårene for vedlikehold.
- Vi kobler til overvåking av kunden og fjerner data fra ham for å kunne reise i tilfelle hendelser.
Den første måten - enkle kontroller - er bare en maskin som pinger alle noder på nettverket og sørger for at de svarer riktig. En slik implementering krever ingen endringer i det hele tatt eller minimale kosmetiske endringer i kundens nettverk. Som regel, i et veldig enkelt tilfelle, installerer vi Zabbix direkte til oss selv i et av datasentrene (heldigvis har vi to av dem på CROC-kontoret på Volochaevskaya). I et mer komplekst, for eksempel, hvis du bruker ditt eget sikre nettverk - til en av maskinene i kundens datasenter:

Zabbix kan brukes mer komplisert, for eksempel har den agenter som er installert på * nix og win noder og viser systemovervåking, samt ekstern kontrollmodus (med støtte for SNMP-protokollen). Likevel, hvis en virksomhet trenger noe lignende, så har de enten allerede sin egen overvåking, eller så velges en mer funksjonsrik løsning. Selvfølgelig er dette ikke lenger åpen kildekode, og det koster penger, men selv en banal nøyaktig beholdning slår allerede kostnadene med omtrent en tredjedel.
Dette gjør vi også, men dette er kollegenes historie. Her sendte de et par skjermbilder av Infosim:


Jeg er en avataroperatør, så jeg skal fortelle deg mer om arbeidet mitt.
Hvordan ser en typisk hendelse ut?
Foran oss er skjermer med følgende generelle status:
På dette anlegget samler Zabbix ganske mye informasjon for oss: batchnummer, serienummer, CPU-belastning, enhetsbeskrivelse, grensesnitttilgjengelighet osv. Alle nødvendig informasjon tilgjengelig fra dette grensesnittet.
En ordinær hendelse begynner som regel med at en av kanalene som fører til for eksempel kundens butikk (som han har 200-300 stykker av over hele landet) faller av. Detaljhandelen er nå godt utviklet, ikke som for sju år siden, så billettkontoret vil fortsette å fungere – det er to kanaler.
Vi tar telefonene og ringer minst tre: Til leverandøren, kraftverket og folk på stedet («Ja, vi har lastet inn armaturer her, noens kabel ble rørt ... Å, din? Vel, det er bra at vi fant den").
Som regel, uten overvåking, ville timer eller dager gått før en eskalering - de samme backupkanalene blir ikke alltid sjekket. Vi vet det med en gang, og vi drar med en gang. Hvis det er tilleggsinformasjon i tillegg til ping (for eksempel en modell av et buggy-jern), fullfører vi umiddelbart feltingeniøren med de nødvendige delene. Videre allerede på plass.
Den nest hyppigste vanlige samtalen er feil på en av terminalene for brukere, for eksempel en DECT-telefon eller en Wi-Fi-ruter som distribuerte nettverket til kontoret. Her lærer vi om problemet fra overvåking og mottar nesten umiddelbart en samtale med detaljer. Noen ganger legger ikke samtalen til noe nytt ("Jeg tar telefonen, noe ringer ikke"), noen ganger er det veldig nyttig ("Vi droppet det fra bordet"). Det er klart at i det andre tilfellet er dette tydeligvis ikke et linjeskift.
Utstyr i Moskva er hentet fra våre varme reservelagre, vi har flere typer av dem:

Kunder har vanligvis sine egne lager av komponenter som ofte svikter – kontortelefoner, strømforsyninger, vifter og så videre. Skal du levere noe som ikke er på plass, ikke til Moskva, går vi vanligvis selv (fordi installasjon). For eksempel hadde jeg en natttur til Nizhny Tagil.
Dersom kunden har egen overvåking kan de laste opp data til oss. Noen ganger distribuerer vi Zabbix i polling-modus, bare for å sikre åpenhet og SLA-kontroll (dette er også gratis for kunden). Vi installerer ikke ekstra sensorer (dette gjøres av kolleger som sørger for kontinuitet produksjonsprosesser), men vi kan koble til dem hvis protokollene ikke er eksotiske.
Generelt berører vi ikke kundens infrastruktur, vi støtter den som den er.
Av erfaring kan jeg si at de ti siste kundene gikk over til ekstern support på grunn av at vi er veldig forutsigbare med tanke på kostnader. Tydelig budsjettering, god saksbehandling, rapport på hver forespørsel, SLA, utstyrsrapporter, forebyggende vedlikehold. Ideelt sett er vi selvfølgelig for CIO for en kunde som rengjøringsmidler - vi kommer og gjør det, alt er rent, vi distraherer ikke.
En annen ting som er verdt å merke seg er at i noen store selskaper blir lagerbeholdning et reelt problem, og noen ganger tiltrekkes vi bare av å gjennomføre det. I tillegg gjør vi lagring av konfigurasjoner og deres administrasjon, noe som er praktisk for forskjellige flyttinger og omkoblinger. Men igjen, inn vanskelige saker det er ikke meg heller – vi har et spesielt team som transporterer datasentre.
Og enda et viktig poeng: vår avdeling har ikke å gjøre med kritisk infrastruktur. Alt inne i datasentrene og alt som er bank-forsikringsoperatør, pluss kjernesystemene i detaljhandelen - dette er et X-team. Her er gutta.
Mer øvelse
Mange moderne enheter er i stand til å gi mye serviceinformasjon. For eksempel er nettverksskrivere veldig enkle å overvåke nivået av toner i kassetten. Du kan regne med utskiftingsperioden på forhånd, pluss ha 5-10 % varsel (hvis kontoret plutselig begynner å skrive rasende ikke i standardskjemaet) - og umiddelbart sende en enikey før regnskapsavdelingen begynner å få panikk.Svært ofte blir årsstatistikk tatt fra oss, noe som gjøres av samme overvåkingssystem pluss oss. I tilfellet Zabbix er dette enkel kostnadsplanlegging og forståelse av hva som har gått galt, og i tilfellet Infosim er det også materiell for å beregne skalering for et år, laste inn admins og alt mulig annet. Det er energiforbruk i statistikken - det siste året begynte nesten alle å spørre ham, tilsynelatende for å spre interne kostnader mellom avdelingene.
Noen ganger oppnås ekte heroiske redninger. Slike situasjoner er svært sjeldne, men etter det jeg husker i år så vi rundt klokken 03.00 at temperaturen steg til 55 grader på cisco-bryteren. I det fjerne serverrommet var det "dumme" klimaanlegg uten overvåking, og de sviktet. Vi ringte umiddelbart en kjøleingeniør (ikke vår) og ringte kundens vakthavende administrator. Han la ut noen ikke-kritiske tjenester og holdt serverrommet fra termisk nedbrudd til fyren kom med mobilt klimaanlegg, og deretter reparerer personalet.
Polycoms og annet kostbart videokonferanseutstyr overvåker batteriladenivået før konferanser veldig godt, noe som også er viktig.
Alle trenger overvåking og diagnostikk. Som regel er det langt og vanskelig å implementere uten erfaring: systemene er enten ekstremt enkle og forhåndskonfigurerte, eller på størrelse med et hangarskip og med en haug med standardrapporter. Å skjerpe seg med en fil for bedriften, finne på implementeringen av oppgavene deres for den interne IT-avdelingen og vise den informasjonen de trenger mest, pluss å holde hele historikken oppdatert er en rake hvis det ikke er noen implementeringserfaring. Når vi jobber med overvåkingssystemer velger vi den gyldne middelvei mellom gratis og toppløsninger - som regel ikke de mest populære og "tykke" leverandørene, men løser helt klart problemet.
En gang var det en ganske atypisk behandling. Kunden måtte gi ruteren til noen av sine separate avdelinger, og akkurat i henhold til inventaret. Ruteren hadde en modul med spesifisert serienummer. Da ruteren begynte å gjøre klar for veien, viste det seg at denne modulen manglet. Og ingen kan finne den. Problemet forverres litt av det faktum at ingeniøren som jobbet med denne grenen i fjor allerede er pensjonist og har dratt for å bo med barnebarna i en annen by. De tok kontakt og ba om å se. Heldigvis ga maskinvaren rapporter om serienumre, og Infosim gjorde en inventar, så vi fant denne modulen i infrastrukturen på et par minutter og beskrev topologien. Rømlingen ble sporet opp via kabel - han var på et annet serverrom i et skap. Bevegelsens historie viste at han kom dit etter feilen i en lignende modul.

En ramme fra en spillefilm om Hottabych, som nøyaktig beskriver befolkningens holdning til kameraer
Mange kamerahendelser. En gang sviktet 3 kameraer samtidig. Kabelbrudd i en av seksjonene. Installatøren blåste en ny inn i korrugeringen, to av de tre kamrene reiste seg etter en serie med sjamanisme. Og den tredje er ikke det. Dessuten er det ikke klart hvor hun er i det hele tatt. Jeg hever videostrømmen - de siste bildene rett før høsten - 4 om morgenen kommer tre menn med skjerf i ansiktet opp, noe lyst under, kameraet rister mye, faller.
En gang satte vi opp kameraet, som skulle fokusere på "harene" som klatrer over gjerdet. Mens vi kjørte, tenkte vi på hvordan vi skulle utpeke punktet der inntrengeren skulle dukke opp. Det kom ikke til nytte - i løpet av de 15 minuttene vi var der, kom 30 personer inn i objektet bare på det punktet vi trengte. Rett opp bord.
Som jeg allerede ga et eksempel ovenfor, er ikke historien om den revne bygningen en spøk. En gang forsvant koblingen til utstyret. På plass - det er ingen paviljong der kobber passerte. Paviljongen ble revet, kabelen var borte. Vi så at ruteren var død. Installatøren kom, begynte å lete - og avstanden mellom nodene er et par kilometer. Han har en Vipnet-tester i settet sitt, standarden - den ringte fra en kontakt, den ringte fra en annen - han gikk på jakt. Vanligvis er problemet umiddelbart synlig.

Sporing av kabelen: dette er korrugert optikk, en fortsettelse av historien helt fra toppen av innlegget om knuten. Her, til slutt, i tillegg til den helt fantastiske installasjonen, var problemet at kabelen hadde flyttet seg vekk fra festene. Her klatre alt og alt, og løsne metallkonstruksjoner. Omtrent fem tusende representant for proletariatet brøt optikken.
Ved ett anlegg ble alle noder slått av omtrent en gang i uken. Og samtidig. Vi har lett etter et mønster ganske lenge. Installasjonsprogrammet fant følgende:
- Problemet oppstår alltid i skiftet til samme person.
- Han skiller seg fra andre ved at han har en veldig tung frakk.
- En automatisk maskin er montert bak en kleshenger.
- Noen tok dekselet på maskinen for lenge siden, tilbake i forhistorisk tid.
- Når denne kameraten kommer til anlegget, henger han opp klærne, og hun slår av maskinene.
- Han slår dem umiddelbart på igjen.
Utstyr ble slått av på en og samme tid på samme tid om natten. Det viste seg at lokale håndverkere koblet til strømforsyningen vår, tok frem en skjøteledning og stakk en vannkoker og en elektrisk komfyr der inne. Når disse enhetene fungerer samtidig, blir hele paviljongen slått ut.
I en av butikkene i vårt enorme land falt hele nettverket stadig med stengingen av skiftet. Installatøren så at all strøm ble brakt til lysledningen. Så snart takbelysningen til hallen (som bruker mye energi) slås av i butikken, slås alt nettverksutstyr av.
Det var et tilfelle at vaktmesteren avbrøt kabelen med en spade.
Ofte ser vi bare kobber som ligger med en revet bølge. En gang, mellom to verksteder, sendte lokale håndverkere ganske enkelt en tvunnet kabel uten beskyttelse.
Bort fra sivilisasjonen klager ansatte ofte over at de blir utsatt for "vårt" utstyr. Sentralbord på enkelte fjerntliggende steder kan være i samme rom som den som har vakt. Følgelig kom vi et par ganger over skadelige bestemødre som ved krok eller skurk slo dem av i begynnelsen av skiftet.
En annen fjern by hengte en mopp på optikken. De brøt av korrugeringen fra veggen, begynte å bruke den som festemidler for utstyr.

I dette tilfellet er det helt klart problemer med ernæring.
Hva "stor" overvåking kan gjøre
Jeg skal kort snakke om mulighetene til mer seriøse systemer, ved å bruke eksemplet med Infosim-installasjoner. Det er 4 løsninger kombinert til én plattform:- Feilhåndtering - feilkontroll og hendelseskorrelasjon.
- Resultatstyring.
- Inventar og automatisk topologioppdagelse.
- Konfigurasjonsstyring.
Separat, om inventaret. Modulen viser ikke bare listen, men bygger også selve topologien (minst i 95 % av tilfellene prøver den og får det til). Den lar deg også ha en oppdatert database over brukt og ledig IT-utstyr (nettverk, serverutstyr, etc.), for å erstatte utdatert utstyr i tide (EOS / EOL). Generelt er det praktisk for store bedrifter, men i små bedrifter gjøres mye av dette for hånd.
Eksempler på rapporter:
- Rapporter etter type OS, firmware, modeller og utstyrsprodusenter;
- Rapporter om antall ledige porter på hver svitsj i nettverket / av valgt produsent / etter modell / etter subnett, etc.;
- Rapporter om nylig lagt til enheter for en spesifisert periode;
- Advarsel om lite toner i skriveren;
- Evaluering av kommunikasjonskanalens egnethet for trafikk følsomme for forsinkelser og tap, aktive og passive metoder;
- Sporing av kvaliteten og tilgjengeligheten til kommunikasjonskanaler (SLA) - generering av rapporter om kvaliteten på kommunikasjonskanaler, fordelt på teleoperatører;
- Feilkontroll og henimplementeres gjennom Root-Cause Analysis-mekanismen (uten at administratorer trenger å skrive regler) og Alarm States Machine-mekanismen. Root-Cause Analysis er en analyse av årsaken til en ulykke basert på følgende prosedyrer: 1. automatisk deteksjon og lokalisering av feilstedet; 2. redusere antall nødhendelser til én nøkkel; 3. identifisere konsekvensene av en svikt - hvem og hva som ble berørt av svikten.

Stablenet - Embedded Agent (SNEA) - en datamaskin som er litt større enn en pakke sigaretter.
Installasjonen utføres i minibanker, eller dedikerte nettverkssegmenter der tilgjengelighetstesting er nødvendig. Med deres hjelp utføres lasttesting.
Skyovervåking
En annen installasjonsmodell er SaaS i skyen. Laget for én global kunde (et selskap med en kontinuerlig produksjonssyklus med en distribusjonsgeografi fra Europa til Sibir).Dusinvis av fasiliteter, inkludert fabrikker og varehus ferdige produkter. Hvis kanalene deres falt, og støtten deres ble utført fra utenlandske kontorer, begynte forsendelsesforsinkelser, som langs bølgen førte til ytterligere tap. Alt arbeid ble utført på forespørsel og det ble brukt mye tid på å etterforske hendelsen.
Vi satte opp overvåking spesifikt for dem, og fullførte den på en rekke nettsteder i henhold til spesifikasjonene for ruting og maskinvare. Alt dette ble gjort i CROC-skyen. De fullførte og leverte prosjektet veldig raskt.
Resultatet er:
- På grunn av delvis overføring av styring av nettverksinfrastrukturen, var det mulig å optimalisere minst 50 %. Utilgjengelighet av utstyr, kanalbelastning, overskridelse av parameterne anbefalt av produsenten: alt dette fikses innen 5-10 minutter, diagnostisert og eliminert innen en time.
- Når kunden mottar en tjeneste fra skyen, overfører kunden kapitalkostnadene ved å distribuere nettverksovervåkingssystemet til driftskostnader for en abonnementsavgift for tjenesten vår, som kan frafalles når som helst.
Fordelen med skyen er at vi i vår beslutning står så å si over nettverket deres og kan se på alt som skjer mer objektivt. På den tiden, hvis vi var inne i nettverket, ville vi bare se bildet opp til feilnoden, og hva som skjer bak det, ville vi ikke lenger vite.
Et par siste bilder
Dette er "morgenpuslespillet":
Og dette er skatten vi fant:

Dette er hva som var i brystet:

Og til slutt, om den morsomste utflukten. Jeg dro en gang til et butikklokale.
Følgende skjedde der: Først begynte det å dryppe fra taket og ned på det underliggende taket. Så dannet det seg en innsjø i undertaket, som eroderte og knuste en av flisene. Som et resultat fosset alt dette til elektrikeren. Da vet jeg ikke nøyaktig hva som skjedde, men et sted i naborommet ble det kortslutning, og det startet en brann. Først fungerte pulverslukningsapparater, og så kom brannmenn og fylte alt med skum. Jeg kom etter dem for demontering. Jeg må si at tsiska 2960 fikk det rett etter alt dette - jeg var i stand til å plukke opp konfigurasjonen og sende enheten til reparasjon.
En gang til, under utløsningen av pulversystemet, ble Tsiskovsky 3745 i en boks nesten helt fylt med pulver. Alle grensesnitt var fulle - 2 x 48 porter. Den måtte med på stedet. Husket tidligere sak, bestemte seg for å prøve å fjerne konfigurasjonene "hot", ristet den ut, renset den så godt de kunne. Vi skrudde den på - først sa enheten "pff" og nyste mot oss med en stor strøm av pulver. Og så buldret det og reiste seg.
ekkoforespørsel
En ekkoforespørsel (ping) er et diagnoseverktøy som brukes til å finne ut om en bestemt vert er tilgjengelig på et IP-nettverk. Ekkoforespørselen gjøres ved å bruke ICMP-protokollen (Internet Control Message Protocol). Denne protokollen brukes til å sende en ekkoforespørsel til verten som kontrolleres. Verten må konfigureres til å akseptere ICMP-pakker.
Undersøkelse
etter ekkoforespørsel
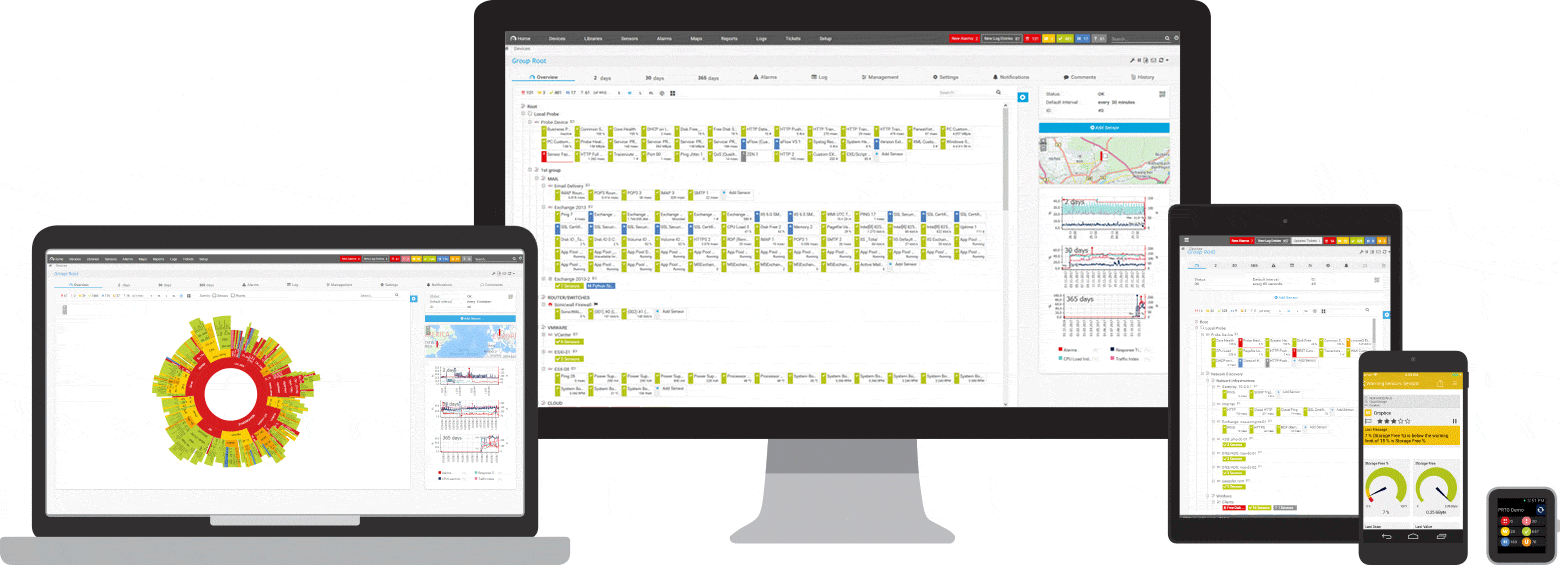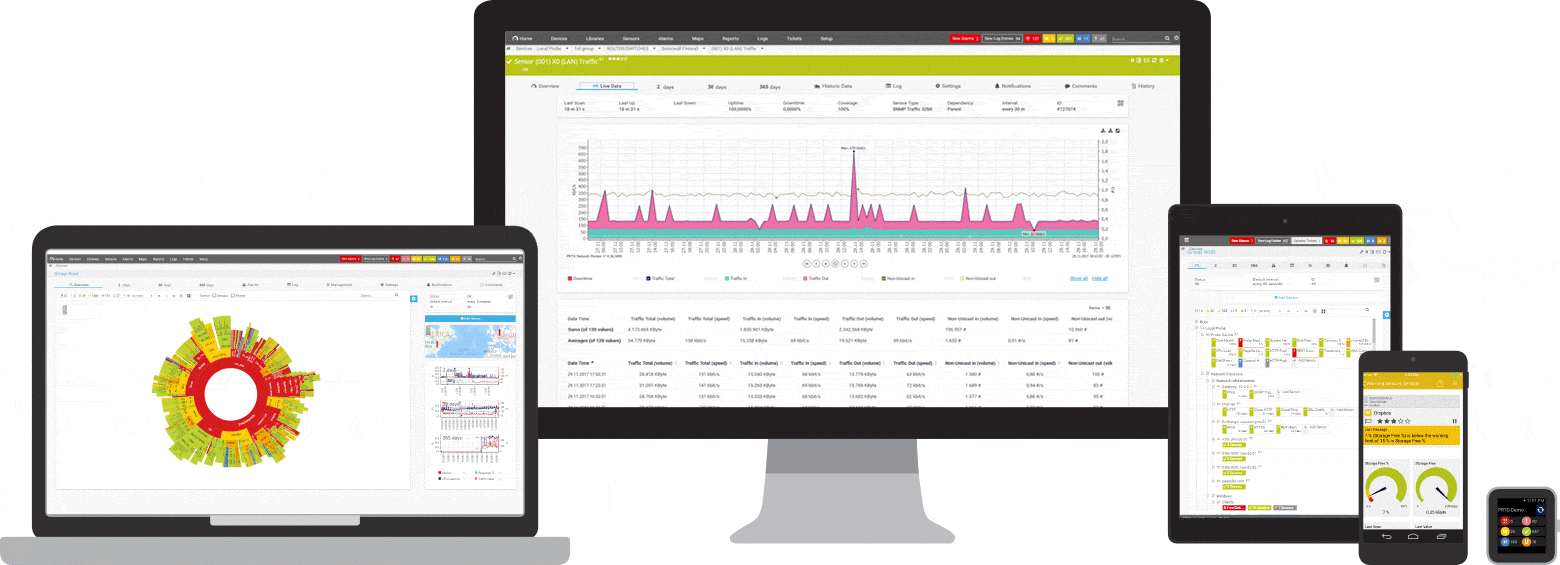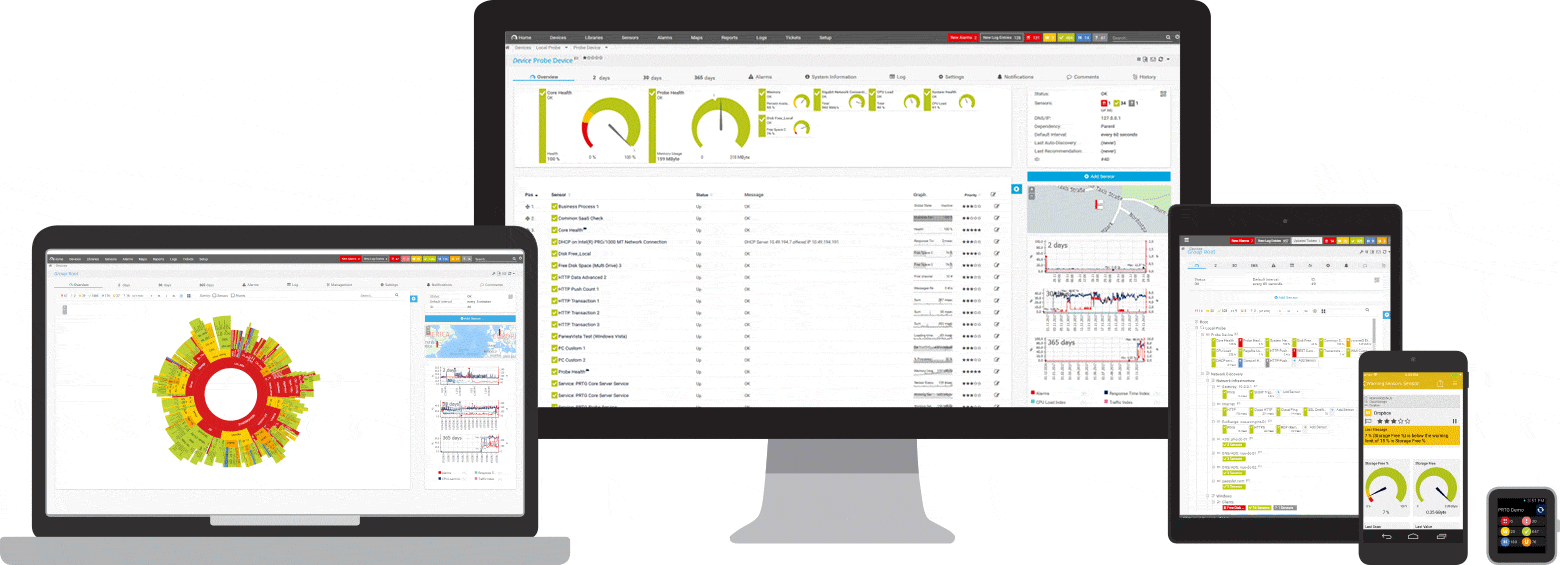
PRTG er et ping- og nettverksovervåkingsverktøy for Windows. Den er kompatibel med alle større Windows-systemer, inkludert Windows Server 2012 R2 og Windows 10.
PRTG er et kraftig verktøy for hele nettverket. For servere, rutere, svitsjer, oppetid og skytilkoblinger holder PRTG styr på alt slik at du kan ta bryet med administrasjonen. Ping-sensoren, samt SNMP-, NetFlow- og pakkesniff-sensorer brukes til å samle detaljert informasjon om nettverkstilgjengelighet og arbeidsbelastning.
PRTG har et tilpassbart innebygd alarmsystem som varsler deg raskt om problemer. Ping-sensoren er konfigurert som primærsensor for nettverksenheter. Hvis denne sensoren svikter, settes alle andre sensorer på enheten i hvilemodus. Dette betyr at i stedet for en strøm av varselmeldinger, vil du kun motta ett varsel.
Når som helst, på din forespørsel, kan du vise på PRTG-dashbordet kort anmeldelse. Du vil umiddelbart se om alt er i orden. Dashbordet kan tilpasses for å passe dine spesifikke behov. Bort fra arbeidsplassen, for eksempel når du jobber i et serverrom, er tilgang til PRTG mulig gjennom en smarttelefonapplikasjon, og du vil aldri gå glipp av et eneste arrangement.
Innledende overvåking konfigureres umiddelbart under installasjonen. Dette er mulig takket være funksjonen for automatisk oppdagelse: PRTG pinger dine private IP-adresser og oppretter automatisk sensorer for tilgjengelige enheter. Når du åpner PRTG for første gang, kan du umiddelbart sjekke tilgjengeligheten til nettverket ditt.
PRTG-programmet har en transparent lisensieringsmodell. Du kan teste PRTG gratis. Ekkoforespørselssensoren og alarmfunksjonen er også inkludert i gratisversjonen og har ubegrenset brukstid. Hvis bedriften eller nettverket ditt trenger flere funksjoner, er det enkelt å oppgradere lisensen.
Skjermbilder
En kort introduksjon til PRTG: Ping-overvåking



Dine ping-sensorer i full oversikt
- selv på farten
PRTG installeres på få minutter og er kompatibel med de fleste mobile enheter.
PRTG kontrollerer disse og mange andre produsenter og applikasjoner for deg
Tre PRTG-sensorer for ping-overvåking
Sensor
ekkoforespørsler
fra skyen
Cloud Ping-sensoren bruker PRTG Cloud til å måle tiden det tar å pinge nettverket ditt fra forskjellige steder rundt om i verden. Denne sensoren lar deg se tilgjengeligheten til nettverket ditt i Asia, Europa og Amerika. Spesielt er denne indikatoren veldig viktig for internasjonale selskaper. .
Ved å kjøpe PRTG-programvaren vil du motta omfattende gratis støtte. Vår oppgave er å løse dine problemer så raskt som mulig! Spesielt for dette har vi sammen med annet materiell utarbeidet treningsvideoer og omfattende guide. Vi tar sikte på å svare på alle supportbilletter innen 24 timer (hverdager). Du finner svar på mange spørsmål i vår kunnskapsbase. For eksempel gir søket «ping-overvåking» 700 resultater. Noen få eksempler:
"Jeg trenger en ping-sensor som kun samler inn informasjon om tilgjengeligheten til enheten, uten å endre statusen. Er det mulig?"
"Kan jeg bygge en sensor for invers ekkoforespørsel?"

"Med PRTG er vi mye mer komfortable med å vite at systemene våre overvåkes kontinuerlig."
Markus Puke, nettverksadministrator, Schüchtermann Clinic (Tyskland)
- Fullversjon av PRTG i 30 dager
- Etter 30 dager - gratisversjon
- For utvidet versjon - kommersiell lisens

| Nettverksovervåkingsprogramvare – versjon 19.2.50.2842 (15. mai 2019) | |
|
Hosting |
Skyversjon også tilgjengelig (PRTG i skyen) |
Språk |
Engelsk, tysk, russisk, spansk, fransk, portugisisk, nederlandsk, japansk og forenklet kinesisk |
Priser |
Frigjør opptil 100 sensorer (priser) |
Omfattende overvåking |
Nettverksenheter, båndbredde, servere, applikasjoner, virtuelle miljøer, eksterne systemer, IoT og mer. |
Støttede leverandører og applikasjoner |
Nettverks- og pingovervåking med PRTG: Tre praktiske casestudier
200 000 administratorer over hele verden stoler på PRTG-programmet. Disse administratorene kan komme fra forskjellige bransjer, men de har alle én ting til felles – et ønske om å sikre og forbedre tilgjengeligheten og ytelsen til nettverkene deres. Tre brukstilfeller:

Zürich flyplass
Zürich flyplass er den største flyplassen i Sveits, så det er spesielt viktig at alle elektroniske systemer fungerer problemfritt. For å gjøre dette mulig implementerte IT-avdelingen PRTG Network Monitor-programvaren fra Paessler AG. Med over 4500 sensorer sikrer dette verktøyet at problemer umiddelbart oppdages og løses umiddelbart av IT-teamet. Tidligere brukte IT-avdelingen en rekke overvåkingsprogrammer. Men til slutt kom ledelsen til at dette programvare uegnet for spesialisert overvåking av operativt og teknisk personell. Eksempel på bruk.

Bauhaus-universitetet, Weimar
IT-systemene til Bauhaus-universitetet i Weimar brukes av 5000 studenter og 400 ansatte. Tidligere ble en isolert løsning basert på Nagios brukt for å overvåke universitetsnettverket. Systemet var teknisk utdatert og klarte ikke å møte behovene til utdanningsinstitusjonens IT-infrastruktur. Infrastrukturoppgraderinger vil være ekstremt kostbare. I stedet vendte universitetet seg til nye nettverksovervåkingsløsninger. IT-lederne ønsket et omfattende programvareprodukt som var brukervennlig, enkelt å installere og kostnadseffektivt. Derfor valgte de PRTG. Eksempel på bruk.

Offentlige tjenester i byen Frankenthal
Litt mer enn 200 ansatte i de offentlige tjenestene i byen Frankenthal er ansvarlige for forsyningen av elektrisitet, gass og vann til private forbrukere og organisasjoner. Organisasjonen, med alle sine bygninger, er også avhengig av en lokalt distribuert infrastruktur, som består av cirka 80 servere og 200 tilkoblede enheter. Frankenthals IT-ledere lette etter rimelig programvare for å møte deres spesifikke behov. Først satte IT opp en gratis prøveversjon av PRTG. Frankenthals offentlige tjenester bruker i dag rundt 1500 sensorer for å overvåke blant annet offentlige svømmebassenger. Eksempel på bruk.

Praktiske råd. Fortell meg, Greg, har du noen anbefalinger for å overvåke ping?
«Pingback-sensorer er sannsynligvis de viktigste elementene i nettverksovervåking. De må konfigureres riktig, spesielt med tanke på tilkoblingene dine. Hvis du for eksempel overvåker driften av en virtuell maskin, er det nyttig å plassere en ping-sensor i forbindelsen til verten. Hvis en node mislykkes, vil du ikke motta et varsel for hver virtuell maskin som er koblet til den. I tillegg kan ping-sensorer være gode indikatorer på at nettverksbanen til verten eller Internett fungerer som den skal, spesielt i scenarier med høy tilgjengelighet eller failover.»
Greg Campion, systemadministrator, PAESSLER AG
EMCO Ping Monitor. Gratis adminassistent
Hvis infrastrukturen din har opptil 5 virtualiseringsverter, kan du bruke gratisversjonen.
Ping Monitor: Network Connection State Monitoring Tool (gratis for 5 verter)
Info:
Pålitelig overvåkingsverktøy for automatisk å sjekke tilkoblingen til nettverket av verter ved å utføre en kommando ping.
Wiki:
Ping er et verktøy for å teste tilkoblinger på TCP/IP-baserte nettverk, samt fellesnavnet for selve forespørselen.
Verktøyet sender forespørsler (ICMP Echo-Request) av ICMP-protokollen til den angitte verten og fanger opp innkommende svar (ICMP Echo-Reply). Tiden mellom sending av en forespørsel og mottak av svar (RTT, fra engelsk Round Trip Time) lar deg bestemme rundtursforsinkelsene (RTT) langs ruten og hyppigheten av pakketap, det vil si indirekte bestemme overbelastningen på datakanaler og mellomenheter.
Ping-programmet er et av de viktigste diagnoseverktøyene i TCP / IP-nettverk og er inkludert i leveransen av alle moderne nettverk operativsystemer.
https://ru.wikipedia.org/wiki/Ping
Programmet, ved å sende vanlige ICMP-forespørsler, overvåker nettverkstilkoblinger og varsler deg om oppdaget gjenoppretting/fall av kanaler. EMCO Ping Monitor gir tilkoblingsstatistikkdata, inkludert oppetid, tjenesteavbrudd, ping-feil, etc.


Et robust ping-overvåkingsverktøy for automatisk kontroll av tilkobling til nettverksverter. Ved å lage vanlige ping overvåker den nettverkstilkoblinger og varsler deg om oppdagede opp-/nedturer. EMCO Ping Monitor gir også informasjon om tilkoblingsstatistikk, inkludert oppetid, strømbrudd, mislykkede ping, etc. Du kan enkelt utvide funksjonaliteten og konfigurere EMCO Ping Monitor til å utføre tilpassede kommandoer eller starte applikasjoner når tilkoblinger går tapt eller gjenopprettes.
Hva er EMCO Ping Monitor?
EMCO Ping Monitor kan fungere i 24/7-modus for å spore tilstandene til tilkoblingen til en eller flere verter. Applikasjonen analyserer ping-svar for å oppdage tilkoblingsbrudd og rapportere tilkoblingsstatistikk. Den kan automatisk oppdage tilkoblingsbrudd og vise Windows Tray-ballonger, spille av lyder og sende e-postvarsler. Den kan også generere rapporter og sende dem via e-post eller lagre som PDF- eller HTML-filer.
Programmet lar deg få informasjon om statusene til alle vertene, sjekke den detaljerte statistikken til en valgt vert og sammenligne ytelsen til forskjellige verter. Programmet lagrer de innsamlede pingdataene i databasen, slik at du kan sjekke statistikk for en valgt tidsperiode. Den tilgjengelige informasjonen inkluderer min/maks/gjennomsnittlig pingtid, pingavvik, liste over tilkoblingsbrudd osv. Denne informasjonen kan representeres som rutenettdata og diagrammer.
EMCO Ping Monitor: Hvordan fungerer det?
EMCO Ping Monitor kan brukes til å utføre ping-overvåking av bare noen få verter eller tusenvis av verter. Alle verter overvåkes i sanntid av dedikerte arbeidstråder, slik at du kan få sanntidsstatistikk og varsler om tilkoblingstilstandsendringer for hver vert. Programmet har ingen spesielle krav til maskinvare - du kan overvåke noen tusen verter på en typisk moderne PC.
Programmet bruker ping for å oppdage tilkoblingsbrudd. Hvis noen få ping mislykkes i en raw - rapporterer den et strømbrudd og varsler deg om problemet. Når tilkoblingen er opprettet og ping begynner å passere - programmet oppdager slutten på strømbruddet og varsler deg om det. Du kan tilpasse strømbrudd og gjenopprette deteksjonsforhold og også varsler som brukes av programmet.
Sammenlign funksjoner og velg utgaven
Programmet er tilgjengelig i tre utgaver med forskjellige sett med funksjoner.
Sammenlign utgaver
Gratis-utgaven lar deg utføre ping-overvåking av opptil 5 verter. Den tillater ikke noen spesifikk konfigurasjon for verter. Det kjører som et Windows-program, så overvåking stoppes hvis du lukker brukergrensesnittet eller logger av Windows.
Gratis for personlig og kommersiell bruk
Profesjonell utgave
Professional-utgaven tillater overvåking av opptil 250 verter samtidig. Hver vert kan ha en egendefinert konfigurasjon som varsling av e-postmottakere eller egendefinerte handlinger som skal utføres ved tapt tilkobling og gjenopprettingshendelser. Den kjører som en Windows-tjeneste, så overvåking fortsetter selv om du lukker brukergrensesnittet eller logger av Windows.
Enterprise Edition
Enterprise-utgaven har ingen begrensninger på antall overvåkede verter. På en moderne PC er det mulig å overvåke 2500+ verter avhengig av maskinvarekonfigurasjonen.
Denne utgaven inkluderer alle tilgjengelige funksjoner og fungerer som en klient/server. Serveren fungerer som en Windows-tjeneste for å sikre ping-overvåking i 24/7-modus. Klienten er et Windows-program som kan koble til en server som kjører på en lokal PC eller til en ekstern server via et LAN eller Internett. Flere klienter kan koble til samme server og arbeide samtidig.
Denne utgaven inkluderer også nettrapporter som gjør det mulig å gjennomgå vertsovervåkingsstatistikk eksternt i en nettleser.
Hovedfunksjonene til EMCO Ping Monitor
Multi-Host Ping-overvåking
Applikasjonen kan overvåke flere verter samtidig. Gratisutgaven av applikasjonen tillater overvåking av opptil fem verter; Professional-utgaven har ingen begrensning for antall overvåkede verter. Overvåking av hver vert fungerer uavhengig av andre verter. Du kan overvåke titusenvis av verter fra en moderne PC.
Deteksjon av tilkoblingsbrudd
Applikasjonen sender ICMP ping-ekkoforespørsler og analyserer ping-ekkosvar for å overvåke tilkoblingstilstanden i 24/7-modus. Hvis det forhåndsinnstilte antallet ping mislykkes på rad, oppdager programmet et tilkoblingsbrudd og varsler deg om problemet. Applikasjonen sporer alle strømbrudd, slik at du kan se når en vert var frakoblet.
Tilkoblingskvalitetsanalyse
Når applikasjonen pinger en overvåket vert, lagrer og samler den data om hver ping, slik at du kan få informasjon om minimum, maksimum og gjennomsnittlig ping-svartid og ping-svaravviket fra gjennomsnittet for enhver rapporteringsperiode. Det lar deg anslå kvaliteten på nettverkstilkoblingen.
Fleksible varsler
Hvis du ønsker å motta varsler om tilkobling tapt, tilkobling gjenopprettet og andre hendelser oppdaget av applikasjonen, kan du konfigurere applikasjonen til å sende e-postvarsler, spille av lyder og vise Windows Tray-ballonger. Applikasjonen kan sende ett enkelt varsel av hvilken som helst type eller gjenta varsler flere ganger.
Diagrammer og rapporter
All statistisk informasjon samlet inn av applikasjonen kan representeres visuelt med diagrammer. Du kan se ping- og oppetidsstatistikken for en enkelt vert og sammenligne ytelsen til flere verter på diagrammer. Applikasjonen kan automatisk generere rapporter i forskjellige formater med jevne mellomrom for å representere vertsstatistikken.
Egendefinerte handlinger
Du kan integrere applikasjonen med ekstern programvare ved å kjøre eksterne skript eller kjørbare filer når tilkoblinger går tapt eller gjenopprettes eller i tilfelle andre hendelser. Du kan for eksempel konfigurere applikasjonen til å kjøre et eksternt kommandolinjeverktøy for å sende SMS-varsler om eventuelle endringer i vertsstatusene.
Ved utseendet til denne optikken, som går gjennom skogen til samleren, kan vi konkludere med at installatøren ikke fulgte teknologien litt. Festet på bildet antyder også at han sannsynligvis er en sjømann - en marineknute.
Jeg er på det fysiske nettverkshelseteamet, med andre ord teknisk støtte, som har ansvar for at lysene på ruterne blinker som de skal. Vi har under vingen ulike store selskaper med infrastruktur over hele landet. Vi klatrer ikke inne i deres virksomhet, vår oppgave er å sørge for at nettet fungerer på det fysiske nivået og trafikken går som den skal.
Den generelle betydningen av arbeidet er konstant polling av noder, fjerning av telemetri, testkjøringer (for eksempel sjekke innstillinger for å finne sårbarheter), sikring av helse, overvåking av applikasjoner, trafikk. Noen ganger varelager og andre perversjoner.
Jeg skal fortelle om hvordan det er organisert og et par historier fra turene.
Som det vanligvis er
Teamet vårt sitter på et kontor i Moskva og tar nettverkstelemetri. Faktisk er dette konstante ping av noder, samt mottak av overvåkingsdata hvis maskinvaren er smart. Den vanligste situasjonen er at ping ikke passerer flere ganger på rad. I 80 % av tilfellene for en forhandlerkjede, for eksempel, viser dette seg å være et strømbrudd, så vi, ser dette bildet, gjør følgende:- Først ringer vi leverandøren om ulykker
- Så - til kraftverket om nedstengningen
- Deretter prøver vi å etablere en forbindelse med noen på anlegget (dette er ikke alltid mulig, for eksempel kl. 02.00)
- Og til slutt, hvis det ovennevnte ikke hjalp på 5-10 minutter, forlater vi oss selv eller sender en "avatar" - en kontraktsingeniør som sitter et sted i Izhevsk eller Vladivostok, hvis problemet er der.
- Vi holder konstant kontakt med «avataren» og «leder» den gjennom infrastrukturen – vi har sensorer og servicemanualer, han har tang.
- Så sender ingeniøren oss en rapport med bilde om hva det var.
Dialogen går noen ganger slik:
– Så, forbindelsen er tapt mellom bygg nummer 4 og 5. Sjekk ruteren i den femte.
- Bestilling, inkludert. Det er ingen sammenheng.
- Ok, gå langs kabelen til den fjerde bygningen, det er en annen node.
-... Oppa!
- Hva skjedde?
– Her ble det 4. huset revet.
- Hva??
– Jeg legger ved et bilde til rapporten. Jeg kan ikke restaurere huset i SLA.
Men oftere viser det seg likevel å finne en pause og gjenopprette kanalen.
Omtrent 60 % av turene er "i melken", fordi enten strømforsyningen blir avbrutt (av en spade, arbeidsleder, inntrengere), eller at leverandøren ikke vet om feilen, eller et kortsiktig problem er eliminert før installatøren kommer. Men det er tider hvor vi finner ut av problemet før brukerne og før kundens IT-tjenester, og kommuniserer løsningen før de i det hele tatt skjønner at noe har skjedd. Oftest oppstår slike situasjoner om natten, når aktiviteten i kundebedriftene er lav.
Hvem trenger det og hvorfor
Som regel har ethvert stort selskap sin egen IT-avdeling, som tydelig forstår detaljene og oppgavene. I mellomstore og store virksomheter er arbeidet til «enikeevs» og nettverksingeniører ofte satt ut. Det er bare nyttig og praktisk. For eksempel har én forhandler sine egne veldig kule IT-folk, men de er langt fra å bytte ut rutere og spore opp kabler.Hva gjør vi
- Vi jobber med forespørsler - billetter og panikkanrop.
- Vi gjør forebygging.
- Vi følger anbefalingene fra maskinvareleverandører, for eksempel om vilkårene for vedlikehold.
- Vi kobler til overvåking av kunden og fjerner data fra ham for å kunne reise i tilfelle hendelser.
Den første måten - enkle kontroller - er bare en maskin som pinger alle noder på nettverket og sørger for at de svarer riktig. En slik implementering krever ingen endringer i det hele tatt eller minimale kosmetiske endringer i kundens nettverk. Som regel, i et veldig enkelt tilfelle, installerer vi Zabbix direkte til oss selv i et av datasentrene (heldigvis har vi to av dem på CROC-kontoret på Volochaevskaya). I et mer komplekst, for eksempel, hvis du bruker ditt eget sikre nettverk - til en av maskinene i kundens datasenter:
Zabbix kan brukes mer komplisert, for eksempel har den agenter som er installert på * nix og win noder og viser systemovervåking, samt ekstern kontrollmodus (med støtte for SNMP-protokollen). Likevel, hvis en virksomhet trenger noe lignende, så har de enten allerede sin egen overvåking, eller så velges en mer funksjonsrik løsning. Selvfølgelig er dette ikke lenger åpen kildekode, og det koster penger, men selv en banal nøyaktig beholdning slår allerede kostnadene med omtrent en tredjedel.
Dette gjør vi også, men dette er kollegenes historie. Her sendte de et par skjermbilder av Infosim:
Jeg er en avataroperatør, så jeg skal fortelle deg mer om arbeidet mitt.
Hvordan ser en typisk hendelse ut?
Foran oss er skjermer med følgende generelle status:
På denne siden samler Zabbix ganske mye informasjon for oss: delenummer, serienummer, CPU-bruk, enhetsbeskrivelse, tilgjengelighet av grensesnitt, etc. All nødvendig informasjon er tilgjengelig fra dette grensesnittet.
En ordinær hendelse begynner som regel med at en av kanalene som fører til for eksempel kundens butikk (som han har 200-300 stykker av over hele landet) faller av. Detaljhandelen er nå godt utviklet, ikke som for sju år siden, så billettkontoret vil fortsette å fungere – det er to kanaler.
Vi tar telefonene og ringer minst tre: Til leverandøren, kraftverket og folk på stedet («Ja, vi har lastet inn armaturer her, noens kabel ble rørt ... Å, din? Vel, det er bra at vi fant den").
Som regel, uten overvåking, ville timer eller dager gått før en eskalering - de samme backupkanalene blir ikke alltid sjekket. Vi vet det med en gang, og vi drar med en gang. Hvis det er tilleggsinformasjon i tillegg til ping (for eksempel en modell av et buggy-jern), fullfører vi umiddelbart feltingeniøren med de nødvendige delene. Videre allerede på plass.
Den nest hyppigste vanlige samtalen er feil på en av terminalene for brukere, for eksempel en DECT-telefon eller en Wi-Fi-ruter som distribuerte nettverket til kontoret. Her lærer vi om problemet fra overvåking og mottar nesten umiddelbart en samtale med detaljer. Noen ganger legger ikke samtalen til noe nytt ("Jeg tar telefonen, noe ringer ikke"), noen ganger er det veldig nyttig ("Vi droppet det fra bordet"). Det er klart at i det andre tilfellet er dette tydeligvis ikke et linjeskift.
Utstyr i Moskva er hentet fra våre varme reservelagre, vi har flere typer av dem:
Kunder har vanligvis sine egne lager av komponenter som ofte svikter – kontortelefoner, strømforsyninger, vifter og så videre. Skal du levere noe som ikke er på plass, ikke til Moskva, går vi vanligvis selv (fordi installasjon). For eksempel hadde jeg en natttur til Nizhny Tagil.
Dersom kunden har egen overvåking kan de laste opp data til oss. Noen ganger distribuerer vi Zabbix i polling-modus, bare for å sikre åpenhet og SLA-kontroll (dette er også gratis for kunden). Vi installerer ikke ekstra sensorer (dette gjøres av kollegaer som sikrer kontinuiteten i produksjonsprosessene), men vi kan koble til dem dersom protokollene ikke er eksotiske.
Generelt berører vi ikke kundens infrastruktur, vi støtter den som den er.
Av erfaring kan jeg si at de ti siste kundene gikk over til ekstern support på grunn av at vi er veldig forutsigbare med tanke på kostnader. Tydelig budsjettering, god saksbehandling, rapport på hver forespørsel, SLA, utstyrsrapporter, forebyggende vedlikehold. Ideelt sett er vi selvfølgelig for CIO for en kunde som rengjøringsmidler - vi kommer og gjør det, alt er rent, vi distraherer ikke.
En annen ting som er verdt å merke seg er at i noen store selskaper blir lagerbeholdning et reelt problem, og noen ganger tiltrekkes vi bare av å gjennomføre det. I tillegg gjør vi lagring av konfigurasjoner og deres administrasjon, noe som er praktisk for forskjellige flyttinger og omkoblinger. Men igjen, i vanskelige tilfeller er dette heller ikke meg - vi har en spesiell som transporterer datasentre.
Og enda et viktig poeng: vår avdeling har ikke å gjøre med kritisk infrastruktur. Alt inne i datasentrene og alt som er bank-forsikringsoperatør, pluss kjernesystemene i detaljhandelen - dette er et X-team. disse guttene.
Mer øvelse
Mange moderne enheter er i stand til å gi mye serviceinformasjon. For eksempel er nettverksskrivere veldig enkle å overvåke nivået av toner i kassetten. Du kan regne med utskiftingsperioden på forhånd, pluss ha 5-10 % varsel (hvis kontoret plutselig begynner å skrive rasende ikke i standardskjemaet) - og umiddelbart sende en enikey før regnskapsavdelingen begynner å få panikk.Svært ofte blir årsstatistikk tatt fra oss, noe som gjøres av samme overvåkingssystem pluss oss. I tilfellet Zabbix er dette enkel kostnadsplanlegging og forståelse av hva som har gått galt, og i tilfellet Infosim er det også materiell for å beregne skalering for et år, laste inn admins og alt mulig annet. Det er energiforbruk i statistikken - det siste året begynte nesten alle å spørre ham, tilsynelatende for å spre interne kostnader mellom avdelingene.
Noen ganger oppnås ekte heroiske redninger. Slike situasjoner er svært sjeldne, men etter det jeg husker i år så vi rundt klokken 03.00 at temperaturen steg til 55 grader på cisco-bryteren. I det fjerne serverrommet var det "dumme" klimaanlegg uten overvåking, og de sviktet. Vi ringte umiddelbart en kjøleingeniør (ikke vår) og ringte kundens vakthavende administrator. Han la ut noen ikke-kritiske tjenester og holdt serverrommet fra termisk nedbrudd til fyren kom med et mobilt klimaanlegg, og fikset deretter de vanlige.
Polycoms og annet kostbart videokonferanseutstyr overvåker batteriladenivået før konferanser veldig godt, noe som også er viktig.
Alle trenger overvåking og diagnostikk. Som regel er det langt og vanskelig å implementere uten erfaring: systemene er enten ekstremt enkle og forhåndskonfigurerte, eller på størrelse med et hangarskip og med en haug med standardrapporter. Å skjerpe seg med en fil for bedriften, finne på implementeringen av oppgavene deres for den interne IT-avdelingen og vise den informasjonen de trenger mest, pluss å holde hele historikken oppdatert er en rake hvis det ikke er noen implementeringserfaring. Når vi jobber med overvåkingssystemer velger vi den gyldne middelvei mellom gratis og toppløsninger - som regel ikke de mest populære og "tykke" leverandørene, men løser helt klart problemet.
En gang var det en ganske atypisk behandling. Kunden måtte gi ruteren til noen av sine separate avdelinger, og akkurat i henhold til inventaret. Ruteren hadde en modul med spesifisert serienummer. Da ruteren begynte å gjøre klar for veien, viste det seg at denne modulen manglet. Og ingen kan finne den. Problemet forverres litt av det faktum at ingeniøren som jobbet med denne grenen i fjor allerede er pensjonist og har dratt for å bo med barnebarna i en annen by. De tok kontakt og ba om å se. Heldigvis ga maskinvaren rapporter om serienumre, og Infosim gjorde en inventar, så vi fant denne modulen i infrastrukturen på et par minutter og beskrev topologien. Rømlingen ble sporet opp via kabel - han var på et annet serverrom i et skap. Bevegelsens historie viste at han kom dit etter feilen i en lignende modul.
En ramme fra en spillefilm om Hottabych, som nøyaktig beskriver befolkningens holdning til kameraer
Mange kamerahendelser. En gang sviktet 3 kameraer samtidig. Kabelbrudd i en av seksjonene. Installatøren blåste en ny inn i korrugeringen, to av de tre kamrene reiste seg etter en serie med sjamanisme. Og den tredje er ikke det. Dessuten er det ikke klart hvor hun er i det hele tatt. Jeg hever videostrømmen - de siste bildene rett før høsten - 4 om morgenen kommer tre menn med skjerf i ansiktet opp, noe lyst under, kameraet rister mye, faller.
En gang satte vi opp kameraet, som skulle fokusere på "harene" som klatrer over gjerdet. Mens vi kjørte, tenkte vi på hvordan vi skulle utpeke punktet der inntrengeren skulle dukke opp. Det kom ikke til nytte - i løpet av de 15 minuttene vi var der, kom 30 personer inn i objektet bare på det punktet vi trengte. Rett opp bord.
Som jeg allerede ga et eksempel ovenfor, er ikke historien om den revne bygningen en spøk. En gang forsvant koblingen til utstyret. På plass - det er ingen paviljong der kobber passerte. Paviljongen ble revet, kabelen var borte. Vi så at ruteren var død. Installatøren kom, begynte å lete - og avstanden mellom nodene er et par kilometer. Han har en Vipnet-tester i settet sitt, standarden - den ringte fra en kontakt, den ringte fra en annen - han gikk på jakt. Vanligvis er problemet umiddelbart synlig.
Sporing av kabelen: dette er korrugert optikk, en fortsettelse av historien helt fra toppen av innlegget om knuten. Her, til slutt, i tillegg til den helt fantastiske installasjonen, var problemet at kabelen hadde flyttet seg vekk fra festene. Her klatre alt og alt, og løsne metallkonstruksjoner. Omtrent fem tusende representant for proletariatet brøt optikken.
Ved ett anlegg ble alle noder slått av omtrent en gang i uken. Og samtidig. Vi har lett etter et mønster ganske lenge. Installasjonsprogrammet fant følgende:
- Problemet oppstår alltid i skiftet til samme person.
- Han skiller seg fra andre ved at han har en veldig tung frakk.
- En automatisk maskin er montert bak en kleshenger.
- Noen tok dekselet på maskinen for lenge siden, tilbake i forhistorisk tid.
- Når denne kameraten kommer til anlegget, henger han opp klærne, og hun slår av maskinene.
- Han slår dem umiddelbart på igjen.
Utstyr ble slått av på en og samme tid på samme tid om natten. Det viste seg at lokale håndverkere koblet til strømforsyningen vår, tok frem en skjøteledning og stakk en vannkoker og en elektrisk komfyr der inne. Når disse enhetene fungerer samtidig, blir hele paviljongen slått ut.
I en av butikkene i vårt enorme land falt hele nettverket stadig med stengingen av skiftet. Installatøren så at all strøm ble brakt til lysledningen. Så snart takbelysningen til hallen (som bruker mye energi) slås av i butikken, slås alt nettverksutstyr av.
Det var et tilfelle at vaktmesteren avbrøt kabelen med en spade.
Ofte ser vi bare kobber som ligger med en revet bølge. En gang, mellom to verksteder, sendte lokale håndverkere ganske enkelt en tvunnet kabel uten beskyttelse.
Bort fra sivilisasjonen klager ansatte ofte over at de blir utsatt for "vårt" utstyr. Sentralbord på enkelte fjerntliggende steder kan være i samme rom som den som har vakt. Følgelig kom vi et par ganger over skadelige bestemødre som ved krok eller skurk slo dem av i begynnelsen av skiftet.
En annen fjern by hengte en mopp på optikken. De brøt av korrugeringen fra veggen, begynte å bruke den som festemidler for utstyr.
I dette tilfellet er det helt klart problemer med ernæring.
Hva "stor" overvåking kan gjøre
Jeg skal kort snakke om mulighetene til mer seriøse systemer, ved å bruke eksemplet med Infosim-installasjoner. Det er 4 løsninger kombinert til én plattform:- Feilhåndtering - feilkontroll og hendelseskorrelasjon.
- Resultatstyring.
- Inventar og automatisk topologioppdagelse.
- Konfigurasjonsstyring.
Separat, om inventaret. Modulen viser ikke bare listen, men bygger også selve topologien (minst i 95 % av tilfellene prøver den og får det til). Den lar deg også ha en oppdatert database over brukt og ledig IT-utstyr (nettverk, serverutstyr, etc.), for å erstatte utdatert utstyr i tide (EOS / EOL). Generelt er det praktisk for store bedrifter, men i små bedrifter gjøres mye av dette for hånd.
Eksempler på rapporter:
- Rapporter etter type OS, firmware, modeller og utstyrsprodusenter;
- Rapporter om antall ledige porter på hver svitsj i nettverket / av valgt produsent / etter modell / etter subnett, etc.;
- Rapporter om nylig lagt til enheter for en spesifisert periode;
- Advarsel om lite toner i skriveren;
- Evaluering av kommunikasjonskanalens egnethet for trafikk følsomme for forsinkelser og tap, aktive og passive metoder;
- Sporing av kvaliteten og tilgjengeligheten til kommunikasjonskanaler (SLA) - generering av rapporter om kvaliteten på kommunikasjonskanaler, fordelt på teleoperatører;
- Feilkontroll og henimplementeres gjennom Root-Cause Analysis-mekanismen (uten at administratorer trenger å skrive regler) og Alarm States Machine-mekanismen. Root-Cause Analysis er en analyse av årsaken til en ulykke basert på følgende prosedyrer: 1. automatisk deteksjon og lokalisering av feilstedet; 2. redusere antall nødhendelser til én nøkkel; 3. identifisere konsekvensene av en svikt - hvem og hva som ble berørt av svikten.
Stablenet - Embedded Agent (SNEA) - en datamaskin som er litt større enn en pakke sigaretter.
Installasjonen utføres i minibanker, eller dedikerte nettverkssegmenter der tilgjengelighetstesting er nødvendig. Med deres hjelp utføres lasttesting.
Skyovervåking
En annen installasjonsmodell er SaaS i skyen. Laget for én global kunde (et selskap med en kontinuerlig produksjonssyklus med en distribusjonsgeografi fra Europa til Sibir).Dusinvis av anlegg, inkludert fabrikker og varehus for ferdige produkter. Hvis kanalene deres falt, og støtten deres ble utført fra utenlandske kontorer, begynte forsendelsesforsinkelser, som langs bølgen førte til ytterligere tap. Alt arbeid ble utført på forespørsel og det ble brukt mye tid på å etterforske hendelsen.
Vi satte opp overvåking spesifikt for dem, og fullførte den på en rekke nettsteder i henhold til spesifikasjonene for ruting og maskinvare. Alt dette ble gjort i CROC-skyen. De fullførte og leverte prosjektet veldig raskt.
Resultatet er:
- På grunn av delvis overføring av styring av nettverksinfrastrukturen, var det mulig å optimalisere minst 50 %. Utilgjengelighet av utstyr, kanalbelastning, overskridelse av parameterne anbefalt av produsenten: alt dette fikses innen 5-10 minutter, diagnostisert og eliminert innen en time.
- Når kunden mottar en tjeneste fra skyen, overfører kunden kapitalkostnadene ved å distribuere nettverksovervåkingssystemet til driftskostnader for en abonnementsavgift for tjenesten vår, som kan frafalles når som helst.
Fordelen med skyen er at vi i vår beslutning står så å si over nettverket deres og kan se på alt som skjer mer objektivt. På den tiden, hvis vi var inne i nettverket, ville vi bare se bildet opp til feilnoden, og hva som skjer bak det, ville vi ikke lenger vite.
Et par siste bilder
Dette er "morgenpuslespillet":
Og dette er skatten vi fant:
Dette er hva som var i brystet:
Og til slutt, om den morsomste utflukten. Jeg dro en gang til et butikklokale.
Følgende skjedde der: Først begynte det å dryppe fra taket og ned på det underliggende taket. Så dannet det seg en innsjø i undertaket, som eroderte og knuste en av flisene. Som et resultat fosset alt dette til elektrikeren. Da vet jeg ikke nøyaktig hva som skjedde, men et sted i naborommet ble det kortslutning, og det startet en brann. Først fungerte pulverslukningsapparater, og så kom brannmenn og fylte alt med skum. Jeg kom etter dem for demontering. Jeg må si at tsiska 2960 fikk det rett etter alt dette - jeg var i stand til å plukke opp konfigurasjonen og sende enheten til reparasjon.
En gang til, under utløsningen av pulversystemet, ble Tsiskovsky 3745 i en boks nesten helt fylt med pulver. Alle grensesnitt var fulle - 2 x 48 porter. Den måtte med på stedet. Vi husket det siste tilfellet, bestemte oss for å prøve å fjerne konfigurasjonene "hot", ristet den ut, renset den så godt vi kunne. Vi skrudde den på - først sa enheten "pff" og nyste mot oss med en stor strøm av pulver. Og så buldret det og reiste seg.



